- Sep 14, 2017
-
-
goldmedal authored
[SPARK-21513][SQL][FOLLOWUP] Allow UDF to_json support converting MapType to json for PySpark and SparkR ## What changes were proposed in this pull request? In previous work SPARK-21513, we has allowed `MapType` and `ArrayType` of `MapType`s convert to a json string but only for Scala API. In this follow-up PR, we will make SparkSQL support it for PySpark and SparkR, too. We also fix some little bugs and comments of the previous work in this follow-up PR. ### For PySpark ``` >>> data = [(1, {"name": "Alice"})] >>> df = spark.createDataFrame(data, ("key", "value")) >>> df.select(to_json(df.value).alias("json")).collect() [Row(json=u'{"name":"Alice")'] >>> data = [(1, [{"name": "Alice"}, {"name": "Bob"}])] >>> df = spark.createDataFrame(data, ("key", "value")) >>> df.select(to_json(df.value).alias("json")).collect() [Row(json=u'[{"name":"Alice"},{"name":"Bob"}]')] ``` ### For SparkR ``` # Converts a map into a JSON object df2 <- sql("SELECT map('name', 'Bob')) as people") df2 <- mutate(df2, people_json = to_json(df2$people)) # Converts an array of maps into a JSON array df2 <- sql("SELECT array(map('name', 'Bob'), map('name', 'Alice')) as people") df2 <- mutate(df2, people_json = to_json(df2$people)) ``` ## How was this patch tested? Add unit test cases. cc viirya HyukjinKwon Author: goldmedal <liugs963@gmail.com> Closes #19223 from goldmedal/SPARK-21513-fp-PySaprkAndSparkR. -
Yanbo Liang authored
## What changes were proposed in this pull request? #19197 fixed double caching for MLlib algorithms, but missed PySpark ```OneVsRest```, this PR fixed it. ## How was this patch tested? Existing tests. Author: Yanbo Liang <ybliang8@gmail.com> Closes #19220 from yanboliang/SPARK-18608.
-
Ming Jiang authored
[SPARK-21854] Added LogisticRegressionTrainingSummary for MultinomialLogisticRegression in Python API ## What changes were proposed in this pull request? Added LogisticRegressionTrainingSummary for MultinomialLogisticRegression in Python API ## How was this patch tested? Added unit test Please review http://spark.apache.org/contributing.html before opening a pull request. Author: Ming Jiang <mjiang@fanatics.com> Author: Ming Jiang <jmwdpk@gmail.com> Author: jmwdpk <jmwdpk@gmail.com> Closes #19185 from jmwdpk/SPARK-21854.
-
- Sep 13, 2017
-
-
Sean Owen authored
## What changes were proposed in this pull request? Put Kafka 0.8 support behind a kafka-0-8 profile. ## How was this patch tested? Existing tests, but, until PR builder and Jenkins configs are updated the effect here is to not build or test Kafka 0.8 support at all. Author: Sean Owen <sowen@cloudera.com> Closes #19134 from srowen/SPARK-21893.
-
- Sep 12, 2017
-
-
Ajay Saini authored
# What changes were proposed in this pull request? Added tunable parallelism to the pyspark implementation of one vs. rest classification. Added a parallelism parameter to the Scala implementation of one vs. rest along with functionality for using the parameter to tune the level of parallelism. I take this PR #18281 over because the original author is busy but we need merge this PR soon. After this been merged, we can close #18281 . ## How was this patch tested? Test suite added. Author: Ajay Saini <ajays725@gmail.com> Author: WeichenXu <weichen.xu@databricks.com> Closes #19110 from WeichenXu123/spark-21027.
-
- Sep 11, 2017
-
-
Chunsheng Ji authored
Probability and rawPrediction has been added to MultilayerPerceptronClassifier for Python Add unit test. Author: Chunsheng Ji <chunsheng.ji@gmail.com> Closes #19172 from chunshengji/SPARK-21856.
-
- Sep 10, 2017
-
-
Peter Szalai authored
## What changes were proposed in this pull request? `typeName` classmethod has been fixed by using type -> typeName map. ## How was this patch tested? local build Author: Peter Szalai <szalaipeti.vagyok@gmail.com> Closes #17435 from szalai1/datatype-gettype-fix.
-
- Sep 09, 2017
-
-
Yanbo Liang authored
## What changes were proposed in this pull request? Correct DataFrame doc. ## How was this patch tested? Only doc change, no tests. Author: Yanbo Liang <ybliang8@gmail.com> Closes #19173 from yanboliang/df-doc.
-
- Sep 08, 2017
-
-
Xin Ren authored
https://issues.apache.org/jira/browse/SPARK-19866 ## What changes were proposed in this pull request? Add Python API for findSynonymsArray matching Scala API. ## How was this patch tested? Manual test `./python/run-tests --python-executables=python2.7 --modules=pyspark-ml` Author: Xin Ren <iamshrek@126.com> Author: Xin Ren <renxin.ubc@gmail.com> Author: Xin Ren <keypointt@users.noreply.github.com> Closes #17451 from keypointt/SPARK-19866.
-
hyukjinkwon authored
[SPARK-15243][ML][SQL][PYTHON] Add missing support for unicode in Param methods & functions in dataframe ## What changes were proposed in this pull request? This PR proposes to support unicodes in Param methods in ML, other missed functions in DataFrame. For example, this causes a `ValueError` in Python 2.x when param is a unicode string: ```python >>> from pyspark.ml.classification import LogisticRegression >>> lr = LogisticRegression() >>> lr.hasParam("threshold") True >>> lr.hasParam(u"threshold") Traceback (most recent call last): ... raise TypeError("hasParam(): paramName must be a string") TypeError: hasParam(): paramName must be a string ``` This PR is based on https://github.com/apache/spark/pull/13036 ## How was this patch tested? Unit tests in `python/pyspark/ml/tests.py` and `python/pyspark/sql/tests.py`. Author: hyukjinkwon <gurwls223@gmail.com> Author: sethah <seth.hendrickson16@gmail.com> Closes #17096 from HyukjinKwon/SPARK-15243. -
Takuya UESHIN authored
## What changes were proposed in this pull request? `pyspark.sql.tests.SQLTests2` doesn't stop newly created spark context in the test and it might affect the following tests. This pr makes `pyspark.sql.tests.SQLTests2` stop `SparkContext`. ## How was this patch tested? Existing tests. Author: Takuya UESHIN <ueshin@databricks.com> Closes #19158 from ueshin/issues/SPARK-21950.
-
- Sep 06, 2017
-
-
Tucker Beck authored
## Problem Description When pyspark is listed as a dependency of another package, installing the other package will cause an install failure in pyspark. When the other package is being installed, pyspark's setup_requires requirements are installed including pypandoc. Thus, the exception handling on setup.py:152 does not work because the pypandoc module is indeed available. However, the pypandoc.convert() function fails if pandoc itself is not installed (in our use cases it is not). This raises an OSError that is not handled, and setup fails. The following is a sample failure: ``` $ which pandoc $ pip freeze | grep pypandoc pypandoc==1.4 $ pip install pyspark Collecting pyspark Downloading pyspark-2.2.0.post0.tar.gz (188.3MB) 100% |████████████████████████████████| 188.3MB 16.8MB/s Complete output from command python setup.py egg_info: Maybe try: sudo apt-get install pandoc See http://johnmacfarlane.net/pandoc/installing.html for installation options --------------------------------------------------------------- Traceback (most recent call last): File "<string>", line 1, in <module> File "/tmp/pip-build-mfnizcwa/pyspark/setup.py", line 151, in <module> long_description = pypandoc.convert('README.md', 'rst') File "/home/tbeck/.virtualenvs/cem/lib/python3.5/site-packages/pypandoc/__init__.py", line 69, in convert outputfile=outputfile, filters=filters) File "/home/tbeck/.virtualenvs/cem/lib/python3.5/site-packages/pypandoc/__init__.py", line 260, in _convert_input _ensure_pandoc_path() File "/home/tbeck/.virtualenvs/cem/lib/python3.5/site-packages/pypandoc/__init__.py", line 544, in _ensure_pandoc_path raise OSError("No pandoc was found: either install pandoc and add it\n" OSError: No pandoc was found: either install pandoc and add it to your PATH or or call pypandoc.download_pandoc(...) or install pypandoc wheels with included pandoc. ---------------------------------------- Command "python setup.py egg_info" failed with error code 1 in /tmp/pip-build-mfnizcwa/pyspark/ ``` ## What changes were proposed in this pull request? This change simply adds an additional exception handler for the OSError that is raised. This allows pyspark to be installed client-side without requiring pandoc to be installed. ## How was this patch tested? I tested this by building a wheel package of pyspark with the change applied. Then, in a clean virtual environment with pypandoc installed but pandoc not available on the system, I installed pyspark from the wheel. Here is the output ``` $ pip freeze | grep pypandoc pypandoc==1.4 $ which pandoc $ pip install --no-cache-dir ../spark/python/dist/pyspark-2.3.0.dev0-py2.py3-none-any.whl Processing /home/tbeck/work/spark/python/dist/pyspark-2.3.0.dev0-py2.py3-none-any.whl Requirement already satisfied: py4j==0.10.6 in /home/tbeck/.virtualenvs/cem/lib/python3.5/site-packages (from pyspark==2.3.0.dev0) Installing collected packages: pyspark Successfully installed pyspark-2.3.0.dev0 ``` Author: Tucker Beck <tucker.beck@rentrakmail.com> Closes #18981 from dusktreader/dusktreader/fix-pandoc-dependency-issue-in-setup_py.
-
- Sep 03, 2017
-
-
hyukjinkwon authored
## What changes were proposed in this pull request? This PR proposes to add a wrapper for `unionByName` API to R and Python as well. **Python** ```python df1 = spark.createDataFrame([[1, 2, 3]], ["col0", "col1", "col2"]) df2 = spark.createDataFrame([[4, 5, 6]], ["col1", "col2", "col0"]) df1.unionByName(df2).show() ``` ``` +----+----+----+ |col0|col1|col3| +----+----+----+ | 1| 2| 3| | 6| 4| 5| +----+----+----+ ``` **R** ```R df1 <- select(createDataFrame(mtcars), "carb", "am", "gear") df2 <- select(createDataFrame(mtcars), "am", "gear", "carb") head(unionByName(limit(df1, 2), limit(df2, 2))) ``` ``` carb am gear 1 4 1 4 2 4 1 4 3 4 1 4 4 4 1 4 ``` ## How was this patch tested? Doctests for Python and unit test added in `test_sparkSQL.R` for R. Author: hyukjinkwon <gurwls223@gmail.com> Closes #19105 from HyukjinKwon/unionByName-r-python.
-
- Sep 01, 2017
-
-
Sean Owen authored
[SPARK-14280][BUILD][WIP] Update change-version.sh and pom.xml to add Scala 2.12 profiles and enable 2.12 compilation …build; fix some things that will be warnings or errors in 2.12; restore Scala 2.12 profile infrastructure ## What changes were proposed in this pull request? This change adds back the infrastructure for a Scala 2.12 build, but does not enable it in the release or Python test scripts. In order to make that meaningful, it also resolves compile errors that the code hits in 2.12 only, in a way that still works with 2.11. It also updates dependencies to the earliest minor release of dependencies whose current version does not yet support Scala 2.12. This is in a sense covered by other JIRAs under the main umbrella, but implemented here. The versions below still work with 2.11, and are the _latest_ maintenance release in the _earliest_ viable minor release. - Scalatest 2.x -> 3.0.3 - Chill 0.8.0 -> 0.8.4 - Clapper 1.0.x -> 1.1.2 - json4s 3.2.x -> 3.4.2 - Jackson 2.6.x -> 2.7.9 (required by json4s) This change does _not_ fully enable a Scala 2.12 build: - It will also require dropping support for Kafka before 0.10. Easy enough, just didn't do it yet here - It will require recreating `SparkILoop` and `Main` for REPL 2.12, which is SPARK-14650. Possible to do here too. What it does do is make changes that resolve much of the remaining gap without affecting the current 2.11 build. ## How was this patch tested? Existing tests and build. Manually tested with `./dev/change-scala-version.sh 2.12` to verify it compiles, modulo the exceptions above. Author: Sean Owen <sowen@cloudera.com> Closes #18645 from srowen/SPARK-14280.
-
- Aug 31, 2017
-
-
hyukjinkwon authored
## What changes were proposed in this pull request? This PR proposes to remove private functions that look not used in the main codes, `_split_schema_abstract`, `_parse_field_abstract`, `_parse_schema_abstract` and `_infer_schema_type`. ## How was this patch tested? Existing tests. Author: hyukjinkwon <gurwls223@gmail.com> Closes #18647 from HyukjinKwon/remove-abstract.
-
hyukjinkwon authored
## What changes were proposed in this pull request? This PR make `DataFrame.sample(...)` can omit `withReplacement` defaulting `False`, consistently with equivalent Scala / Java API. In short, the following examples are allowed: ```python >>> df = spark.range(10) >>> df.sample(0.5).count() 7 >>> df.sample(fraction=0.5).count() 3 >>> df.sample(0.5, seed=42).count() 5 >>> df.sample(fraction=0.5, seed=42).count() 5 ``` In addition, this PR also adds some type checking logics as below: ```python >>> df = spark.range(10) >>> df.sample().count() ... TypeError: withReplacement (optional), fraction (required) and seed (optional) should be a bool, float and number; however, got []. >>> df.sample(True).count() ... TypeError: withReplacement (optional), fraction (required) and seed (optional) should be a bool, float and number; however, got [<type 'bool'>]. >>> df.sample(42).count() ... TypeError: withReplacement (optional), fraction (required) and seed (optional) should be a bool, float and number; however, got [<type 'int'>]. >>> df.sample(fraction=False, seed="a").count() ... TypeError: withReplacement (optional), fraction (required) and seed (optional) should be a bool, float and number; however, got [<type 'bool'>, <type 'str'>]. >>> df.sample(seed=[1]).count() ... TypeError: withReplacement (optional), fraction (required) and seed (optional) should be a bool, float and number; however, got [<type 'list'>]. >>> df.sample(withReplacement="a", fraction=0.5, seed=1) ... TypeError: withReplacement (optional), fraction (required) and seed (optional) should be a bool, float and number; however, got [<type 'str'>, <type 'float'>, <type 'int'>]. ``` ## How was this patch tested? Manually tested, unit tests added in doc tests and manually checked the built documentation for Python. Author: hyukjinkwon <gurwls223@gmail.com> Closes #18999 from HyukjinKwon/SPARK-21779.
-
- Aug 30, 2017
-
-
Liang-Chi Hsieh authored
[SPARK-21534][SQL][PYSPARK] PickleException when creating dataframe from python row with empty bytearray ## What changes were proposed in this pull request? `PickleException` is thrown when creating dataframe from python row with empty bytearray spark.createDataFrame(spark.sql("select unhex('') as xx").rdd.map(lambda x: {"abc": x.xx})).show() net.razorvine.pickle.PickleException: invalid pickle data for bytearray; expected 1 or 2 args, got 0 at net.razorvine.pickle.objects.ByteArrayConstructor.construct(ByteArrayConstructor.java ... `ByteArrayConstructor` doesn't deal with empty byte array pickled by Python3. ## How was this patch tested? Added test. Author: Liang-Chi Hsieh <viirya@gmail.com> Closes #19085 from viirya/SPARK-21534. -
Dongjoon Hyun authored
## What changes were proposed in this pull request? This PR aims to support `spark.sql.orc.compression.codec` like Parquet's `spark.sql.parquet.compression.codec`. Users can use SQLConf to control ORC compression, too. ## How was this patch tested? Pass the Jenkins with new and updated test cases. Author: Dongjoon Hyun <dongjoon@apache.org> Closes #19055 from dongjoon-hyun/SPARK-21839.
-
- Aug 25, 2017
-
-
vinodkc authored
## What changes were proposed in this pull request? This patch adds allowUnquotedControlChars option in JSON data source to allow JSON Strings to contain unquoted control characters (ASCII characters with value less than 32, including tab and line feed characters) ## How was this patch tested? Add new test cases Author: vinodkc <vinod.kc.in@gmail.com> Closes #19008 from vinodkc/br_fix_SPARK-21756.
-
- Aug 24, 2017
-
-
hyukjinkwon authored
[SPARK-19165][PYTHON][SQL] PySpark APIs using columns as arguments should validate input types for column ## What changes were proposed in this pull request? While preparing to take over https://github.com/apache/spark/pull/16537, I realised a (I think) better approach to make the exception handling in one point. This PR proposes to fix `_to_java_column` in `pyspark.sql.column`, which most of functions in `functions.py` and some other APIs use. This `_to_java_column` basically looks not working with other types than `pyspark.sql.column.Column` or string (`str` and `unicode`). If this is not `Column`, then it calls `_create_column_from_name` which calls `functions.col` within JVM: https://github.com/apache/spark/blob/42b9eda80e975d970c3e8da4047b318b83dd269f/sql/core/src/main/scala/org/apache/spark/sql/functions.scala#L76 And it looks we only have `String` one with `col`. So, these should work: ```python >>> from pyspark.sql.column import _to_java_column, Column >>> _to_java_column("a") JavaObject id=o28 >>> _to_java_column(u"a") JavaObject id=o29 >>> _to_java_column(spark.range(1).id) JavaObject id=o33 ``` whereas these do not: ```python >>> _to_java_column(1) ``` ``` ... py4j.protocol.Py4JError: An error occurred while calling z:org.apache.spark.sql.functions.col. Trace: py4j.Py4JException: Method col([class java.lang.Integer]) does not exist ... ``` ```python >>> _to_java_column([]) ``` ``` ... py4j.protocol.Py4JError: An error occurred while calling z:org.apache.spark.sql.functions.col. Trace: py4j.Py4JException: Method col([class java.util.ArrayList]) does not exist ... ``` ```python >>> class A(): pass >>> _to_java_column(A()) ``` ``` ... AttributeError: 'A' object has no attribute '_get_object_id' ``` Meaning most of functions using `_to_java_column` such as `udf` or `to_json` or some other APIs throw an exception as below: ```python >>> from pyspark.sql.functions import udf >>> udf(lambda x: x)(None) ``` ``` ... py4j.protocol.Py4JJavaError: An error occurred while calling z:org.apache.spark.sql.functions.col. : java.lang.NullPointerException ... ``` ```python >>> from pyspark.sql.functions import to_json >>> to_json(None) ``` ``` ... py4j.protocol.Py4JJavaError: An error occurred while calling z:org.apache.spark.sql.functions.col. : java.lang.NullPointerException ... ``` **After this PR**: ```python >>> from pyspark.sql.functions import udf >>> udf(lambda x: x)(None) ... ``` ``` TypeError: Invalid argument, not a string or column: None of type <type 'NoneType'>. For column literals, use 'lit', 'array', 'struct' or 'create_map' functions. ``` ```python >>> from pyspark.sql.functions import to_json >>> to_json(None) ``` ``` ... TypeError: Invalid argument, not a string or column: None of type <type 'NoneType'>. For column literals, use 'lit', 'array', 'struct' or 'create_map' functions. ``` ## How was this patch tested? Unit tests added in `python/pyspark/sql/tests.py` and manual tests. Author: hyukjinkwon <gurwls223@gmail.com> Author: zero323 <zero323@users.noreply.github.com> Closes #19027 from HyukjinKwon/SPARK-19165.
-
- Aug 22, 2017
-
-
Weichen Xu authored
## What changes were proposed in this pull request? Modify MLP model to inherit `ProbabilisticClassificationModel` and so that it can expose the probability column when transforming data. ## How was this patch tested? Test added. Author: WeichenXu <WeichenXu123@outlook.com> Closes #17373 from WeichenXu123/expose_probability_in_mlp_model.
-
Bryan Cutler authored
## What changes were proposed in this pull request? Added call to copy values of Params from Estimator to Model after fit in PySpark ML. This will copy values for any params that are also defined in the Model. Since currently most Models do not define the same params from the Estimator, also added method to create new Params from looking at the Java object if they do not exist in the Python object. This is a temporary fix that can be removed once the PySpark models properly define the params themselves. ## How was this patch tested? Refactored the `check_params` test to optionally check if the model params for Python and Java match and added this check to an existing fitted model that shares params between Estimator and Model. Author: Bryan Cutler <cutlerb@gmail.com> Closes #17849 from BryanCutler/pyspark-models-own-params-SPARK-10931.
-
- Aug 21, 2017
-
-
Kyle Kelley authored
## What changes were proposed in this pull request? Based on https://github.com/apache/spark/pull/18282 by rgbkrk this PR attempts to update to the current released cloudpickle and minimize the difference between Spark cloudpickle and "stock" cloud pickle with the goal of eventually using the stock cloud pickle. Some notable changes: * Import submodules accessed by pickled functions (cloudpipe/cloudpickle#80) * Support recursive functions inside closures (cloudpipe/cloudpickle#89, cloudpipe/cloudpickle#90) * Fix ResourceWarnings and DeprecationWarnings (cloudpipe/cloudpickle#88) * Assume modules with __file__ attribute are not dynamic (cloudpipe/cloudpickle#85) * Make cloudpickle Python 3.6 compatible (cloudpipe/cloudpickle#72) * Allow pickling of builtin methods (cloudpipe/cloudpickle#57) * Add ability to pickle dynamically created modules (cloudpipe/cloudpickle#52) * Support method descriptor (cloudpipe/cloudpickle#46) * No more pickling of closed files, was broken on Python 3 (cloudpipe/cloudpickle#32) * ** Remove non-standard __transient__check (cloudpipe/cloudpickle#110)** -- while we don't use this internally, and have no tests or documentation for its use, downstream code may use __transient__, although it has never been part of the API, if we merge this we should include a note about this in the release notes. * Support for pickling loggers (yay!) (cloudpipe/cloudpickle#96) * BUG: Fix crash when pickling dynamic class cycles. (cloudpipe/cloudpickle#102) ## How was this patch tested? Existing PySpark unit tests + the unit tests from the cloudpickle project on their own. Author: Holden Karau <holden@us.ibm.com> Author: Kyle Kelley <rgbkrk@gmail.com> Closes #18734 from holdenk/holden-rgbkrk-cloudpickle-upgrades.
-
Nick Pentreath authored
Add Python API for `FeatureHasher` transformer. ## How was this patch tested? New doc test. Author: Nick Pentreath <nickp@za.ibm.com> Closes #18970 from MLnick/SPARK-21468-pyspark-hasher.
-
- Aug 18, 2017
-
-
Andrew Ray authored
## What changes were proposed in this pull request? Adds the recently added `summary` method to the python dataframe interface. ## How was this patch tested? Additional inline doctests. Author: Andrew Ray <ray.andrew@gmail.com> Closes #18762 from aray/summary-py.
-
- Aug 15, 2017
-
-
Nicholas Chammas authored
Proposed changes: * Clarify the type error that `Column.substr()` gives. Test plan: * Tested this manually. * Test code: ```python from pyspark.sql.functions import col, lit spark.createDataFrame([['nick']], schema=['name']).select(col('name').substr(0, lit(1))) ``` * Before: ``` TypeError: Can not mix the type ``` * After: ``` TypeError: startPos and length must be the same type. Got <class 'int'> and <class 'pyspark.sql.column.Column'>, respectively. ``` Author: Nicholas Chammas <nicholas.chammas@gmail.com> Closes #18926 from nchammas/SPARK-21712-substr-type-error.
-
- Aug 14, 2017
-
-
byakuinss authored
## What changes were proposed in this pull request? JIRA issue: https://issues.apache.org/jira/browse/SPARK-21658 Add default None for value in `na.replace` since `Dataframe.replace` and `DataframeNaFunctions.replace` are alias. The default values are the same now. ``` >>> df = sqlContext.createDataFrame([('Alice', 10, 80.0)]) >>> df.replace({"Alice": "a"}).first() Row(_1=u'a', _2=10, _3=80.0) >>> df.na.replace({"Alice": "a"}).first() Row(_1=u'a', _2=10, _3=80.0) ``` ## How was this patch tested? Existing tests. cc viirya Author: byakuinss <grace.chinhanyu@gmail.com> Closes #18895 from byakuinss/SPARK-21658.
-
- Aug 12, 2017
-
-
Ajay Saini authored
## What changes were proposed in this pull request? Implemented a Python-only persistence framework for pipelines containing stages that cannot be saved using Java. ## How was this patch tested? Created a custom Python-only UnaryTransformer, included it in a Pipeline, and saved/loaded the pipeline. The loaded pipeline was compared against the original using _compare_pipelines() in tests.py. Author: Ajay Saini <ajays725@gmail.com> Closes #18888 from ajaysaini725/PythonPipelines.
-
- Aug 09, 2017
-
-
bravo-zhang authored
## What changes were proposed in this pull request? Currently `df.na.replace("*", Map[String, String]("NULL" -> null))` will produce exception. This PR enables passing null/None as value in the replacement map in DataFrame.replace(). Note that the replacement map keys and values should still be the same type, while the values can have a mix of null/None and that type. This PR enables following operations for example: `df.na.replace("*", Map[String, String]("NULL" -> null))`(scala) `df.na.replace("*", Map[Any, Any](60 -> null, 70 -> 80))`(scala) `df.na.replace('Alice', None)`(python) `df.na.replace([10, 20])`(python, replacing with None is by default) One use case could be: I want to replace all the empty strings with null/None because they were incorrectly generated and then drop all null/None data `df.na.replace("*", Map("" -> null)).na.drop()`(scala) `df.replace(u'', None).dropna()`(python) ## How was this patch tested? Scala unit test. Python doctest and unit test. Author: bravo-zhang <mzhang1230@gmail.com> Closes #18820 from bravo-zhang/spark-14932. -
peay authored
## What changes were proposed in this pull request? This modification increases the timeout for `serveIterator` (which is not dynamically configurable). This fixes timeout issues in pyspark when using `collect` and similar functions, in cases where Python may take more than a couple seconds to connect. See https://issues.apache.org/jira/browse/SPARK-21551 ## How was this patch tested? Ran the tests. cc rxin Author: peay <peay@protonmail.com> Closes #18752 from peay/spark-21551.
-
WeichenXu authored
## What changes were proposed in this pull request? Update breeze to 0.13.1 for an emergency bugfix in strong wolfe line search https://github.com/scalanlp/breeze/pull/651 ## How was this patch tested? N/A Author: WeichenXu <WeichenXu123@outlook.com> Closes #18797 from WeichenXu123/update-breeze.
-
- Aug 07, 2017
-
-
Yanbo Liang authored
## What changes were proposed in this pull request? PySpark GLR ```model.summary``` should return a printable representation by calling Scala ```toString```. ## How was this patch tested? ``` from pyspark.ml.regression import GeneralizedLinearRegression dataset = spark.read.format("libsvm").load("data/mllib/sample_linear_regression_data.txt") glr = GeneralizedLinearRegression(family="gaussian", link="identity", maxIter=10, regParam=0.3) model = glr.fit(dataset) model.summary ``` Before this PR:  After this PR: 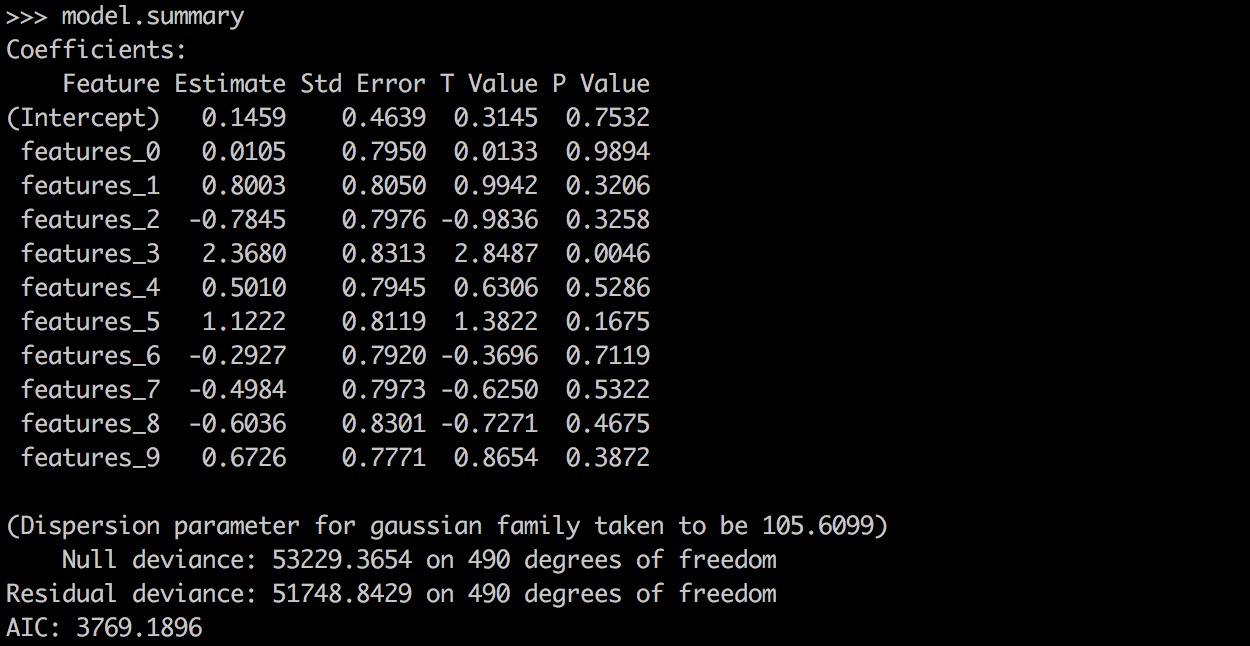 Author: Yanbo Liang <ybliang8@gmail.com> Closes #18870 from yanboliang/spark-19270. -
Ajay Saini authored
## What changes were proposed in this pull request? Added DefaultParamsWriteable, DefaultParamsReadable, DefaultParamsWriter, and DefaultParamsReader to Python to support Python-only persistence of Json-serializable parameters. ## How was this patch tested? Instantiated an estimator with Json-serializable parameters (ex. LogisticRegression), saved it using the added helper functions, and loaded it back, and compared it to the original instance to make sure it is the same. This test was both done in the Python REPL and implemented in the unit tests. Note to reviewers: there are a few excess comments that I left in the code for clarity but will remove before the code is merged to master. Author: Ajay Saini <ajays725@gmail.com> Closes #18742 from ajaysaini725/PythonPersistenceHelperFunctions.
-
Mac authored
## What changes were proposed in this pull request? Enhanced some existing documentation Please review http://spark.apache.org/contributing.html before opening a pull request. Author: Mac <maclockard@gmail.com> Closes #18710 from maclockard/maclockard-patch-1.
-
- Aug 04, 2017
-
-
Ajay Saini authored
## What changes were proposed in this pull request? Implemented UnaryTransformer in Python. ## How was this patch tested? This patch was tested by creating a MockUnaryTransformer class in the unit tests that extends UnaryTransformer and testing that the transform function produced correct output. Author: Ajay Saini <ajays725@gmail.com> Closes #18746 from ajaysaini725/AddPythonUnaryTransformer.
-
- Aug 02, 2017
-
-
zero323 authored
## What changes were proposed in this pull request? Python API for Constrained Logistic Regression based on #17922 , thanks for the original contribution from zero323 . ## How was this patch tested? Unit tests. Author: zero323 <zero323@users.noreply.github.com> Author: Yanbo Liang <ybliang8@gmail.com> Closes #18759 from yanboliang/SPARK-20601.
-
- Aug 01, 2017
-
-
Bryan Cutler authored
## What changes were proposed in this pull request? When using PySpark broadcast variables in a multi-threaded environment, `SparkContext._pickled_broadcast_vars` becomes a shared resource. A race condition can occur when broadcast variables that are pickled from one thread get added to the shared ` _pickled_broadcast_vars` and become part of the python command from another thread. This PR introduces a thread-safe pickled registry using thread local storage so that when python command is pickled (causing the broadcast variable to be pickled and added to the registry) each thread will have their own view of the pickle registry to retrieve and clear the broadcast variables used. ## How was this patch tested? Added a unit test that causes this race condition using another thread. Author: Bryan Cutler <cutlerb@gmail.com> Closes #18695 from BryanCutler/pyspark-bcast-threadsafe-SPARK-12717.
-
Zheng RuiFeng authored
## What changes were proposed in this pull request? GBTs inherit from HasStepSize & LInearSVC/Binarizer from HasThreshold ## How was this patch tested? existing tests Author: Zheng RuiFeng <ruifengz@foxmail.com> Author: Ruifeng Zheng <ruifengz@foxmail.com> Closes #18612 from zhengruifeng/override_HasXXX.
-
- Jul 28, 2017
-
-
hyukjinkwon authored
## What changes were proposed in this pull request? This PR proposes `StructType.fieldNames` that returns a copy of a field name list rather than a (undocumented) `StructType.names`. There are two points here: - API consistency with Scala/Java - Provide a safe way to get the field names. Manipulating these might cause unexpected behaviour as below: ```python from pyspark.sql.types import * struct = StructType([StructField("f1", StringType(), True)]) names = struct.names del names[0] spark.createDataFrame([{"f1": 1}], struct).show() ``` ``` ... java.lang.IllegalStateException: Input row doesn't have expected number of values required by the schema. 1 fields are required while 0 values are provided. at org.apache.spark.sql.execution.python.EvaluatePython$.fromJava(EvaluatePython.scala:138) at org.apache.spark.sql.SparkSession$$anonfun$6.apply(SparkSession.scala:741) at org.apache.spark.sql.SparkSession$$anonfun$6.apply(SparkSession.scala:741) ... ``` ## How was this patch tested? Added tests in `python/pyspark/sql/tests.py`. Author: hyukjinkwon <gurwls223@gmail.com> Closes #18618 from HyukjinKwon/SPARK-20090.
-
- Jul 27, 2017
-
-
Yan Facai (颜发才) authored
## What changes were proposed in this pull request? add `setWeightCol` method for OneVsRest. `weightCol` is ignored if classifier doesn't inherit HasWeightCol trait. ## How was this patch tested? + [x] add an unit test. Author: Yan Facai (颜发才) <facai.yan@gmail.com> Closes #18554 from facaiy/BUG/oneVsRest_missing_weightCol.
-



























")