- Aug 07, 2017
-
-
Jose Torres authored
## What changes were proposed in this pull request? Propagate metadata in attribute replacement during streaming execution. This is necessary for EventTimeWatermarks consuming replaced attributes. ## How was this patch tested? new unit test, which was verified to fail before the fix Author: Jose Torres <joseph-torres@databricks.com> Closes #18840 from joseph-torres/SPARK-21565.
-
Mac authored
## What changes were proposed in this pull request? Enhanced some existing documentation Please review http://spark.apache.org/contributing.html before opening a pull request. Author: Mac <maclockard@gmail.com> Closes #18710 from maclockard/maclockard-patch-1.
-
Xiao Li authored
### What changes were proposed in this pull request? author: BoleynSu closes https://github.com/apache/spark/pull/18836 ```Scala val df = Seq((1, 1)).toDF("i", "j") df.createOrReplaceTempView("T") withSQLConf(SQLConf.AUTO_BROADCASTJOIN_THRESHOLD.key -> "-1") { sql("select * from (select a.i from T a cross join T t where t.i = a.i) as t1 " + "cross join T t2 where t2.i = t1.i").explain(true) } ``` The above code could cause the following exception: ``` SortMergeJoinExec should not take Cross as the JoinType java.lang.IllegalArgumentException: SortMergeJoinExec should not take Cross as the JoinType at org.apache.spark.sql.execution.joins.SortMergeJoinExec.outputOrdering(SortMergeJoinExec.scala:100) ``` Our SortMergeJoinExec supports CROSS. We should not hit such an exception. This PR is to fix the issue. ### How was this patch tested? Modified the two existing test cases. Author: Xiao Li <gatorsmile@gmail.com> Author: Boleyn Su <boleyn.su@gmail.com> Closes #18863 from gatorsmile/pr-18836.
-
zhoukang authored
## What changes were proposed in this pull request? **For moudle below:** common/network-common streaming sql/core sql/catalyst **tests.jar will install or deploy twice.Like:** `[DEBUG] Installing org.apache.spark:spark-streaming_2.11/maven-metadata.xml to /home/mi/.m2/repository/org/apache/spark/spark-streaming_2.11/maven-metadata-local.xml [INFO] Installing /home/mi/Work/Spark/scala2.11/spark/streaming/target/spark-streaming_2.11-2.1.0-mdh2.1.0.1-SNAPSHOT-tests.jar to /home/mi/.m2/repository/org/apache/spark/spark-streaming_2.11/2.1.0-mdh2.1.0.1-SNAPSHOT/spark-streaming_2.11-2.1.0-mdh2.1.0.1-SNAPSHOT-tests.jar [DEBUG] Skipped re-installing /home/mi/Work/Spark/scala2.11/spark/streaming/target/spark-streaming_2.11-2.1.0-mdh2.1.0.1-SNAPSHOT-tests.jar to /home/mi/.m2/repository/org/apache/spark/spark-streaming_2.11/2.1.0-mdh2.1.0.1-SNAPSHOT/spark-streaming_2.11-2.1.0-mdh2.1.0.1-SNAPSHOT-tests.jar, seems unchanged` **The reason is below:** `[DEBUG] (f) artifact = org.apache.spark:spark-streaming_2.11:jar:2.1.0-mdh2.1.0.1-SNAPSHOT [DEBUG] (f) attachedArtifacts = [org.apache.spark:spark-streaming_2.11:test-jar:tests:2.1.0-mdh2.1.0.1-SNAPSHOT, org.apache.spark:spark-streaming_2.11:jar:tests:2.1.0-mdh2.1.0.1-SNAPSHOT, org.apache.spark:spark -streaming_2.11:java-source:sources:2.1.0-mdh2.1.0.1-SNAPSHOT, org.apache.spark:spark-streaming_2.11:java-source:test-sources:2.1.0-mdh2.1.0.1-SNAPSHOT, org.apache.spark:spark-streaming_2.11:javadoc:javadoc:2.1.0 -mdh2.1.0.1-SNAPSHOT]` when executing 'mvn deploy' to nexus during release.I will fail since release nexus can not be overrided. ## How was this patch tested? Execute 'mvn clean install -Pyarn -Phadoop-2.6 -Phadoop-provided -DskipTests' Author: zhoukang <zhoukang199191@gmail.com> Closes #18745 from caneGuy/zhoukang/fix-installtwice.
-
Peng Meng authored
## What changes were proposed in this pull request? comments of parentStats in RF are wrong. parentStats is not only used for the first iteration, it is used with all the iteration for unordered features. ## How was this patch tested? Author: Peng Meng <peng.meng@intel.com> Closes #18832 from mpjlu/fixRFDoc.
-
Stavros Kontopoulos authored
## What changes were proposed in this pull request? Adds a sandbox link per driver in the dispatcher ui with minimal changes after a bug was fixed here: https://issues.apache.org/jira/browse/MESOS-4992 The sandbox uri has the following format: http://<proxy_uri>/#/slaves/\<agent-id\>/ frameworks/ \<scheduler-id\>/executors/\<driver-id\>/browse For dc/os the proxy uri is <dc/os uri>/mesos. For the dc/os deployment scenario and to make things easier I introduced a new config property named `spark.mesos.proxy.baseURL` which should be passed to the dispatcher when launched using --conf. If no such configuration is detected then no sandbox uri is depicted, and there is an empty column with a header (this can be changed so nothing is shown). Within dc/os the base url must be a property for the dispatcher that we should add in the future here: https://github.com/mesosphere/universe/blob/9e7c909c3b8680eeb0494f2a58d5746e3bab18c1/repo/packages/S/spark/26/config.json It is not easy to detect in different environments what is that uri so user should pass it. ## How was this patch tested? Tested with the mesos test suite here: https://github.com/typesafehub/mesos-spark-integration-tests. Attached image shows the ui modification where the sandbox header is added. 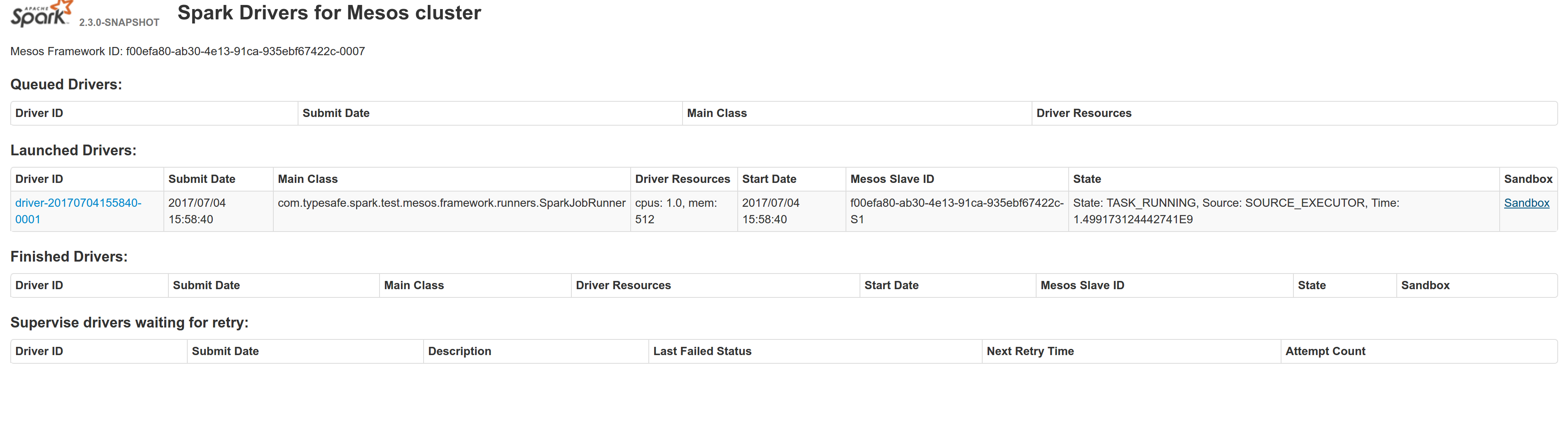 Tested the uri redirection the way it was suggested here: https://issues.apache.org/jira/browse/MESOS-4992 Built mesos 1.4 from the master branch and started the mesos dispatcher with the command: `./sbin/start-mesos-dispatcher.sh --conf spark.mesos.proxy.baseURL=http://localhost:5050 -m mesos://127.0.0.1:5050` Run a spark example: `./bin/spark-submit --class org.apache.spark.examples.SparkPi --master mesos://10.10.1.79:7078 --deploy-mode cluster --executor-memory 2G --total-executor-cores 2 http://<path>/spark-examples_2.11-2.1.1.jar 10` Sandbox uri is shown at the bottom of the page: 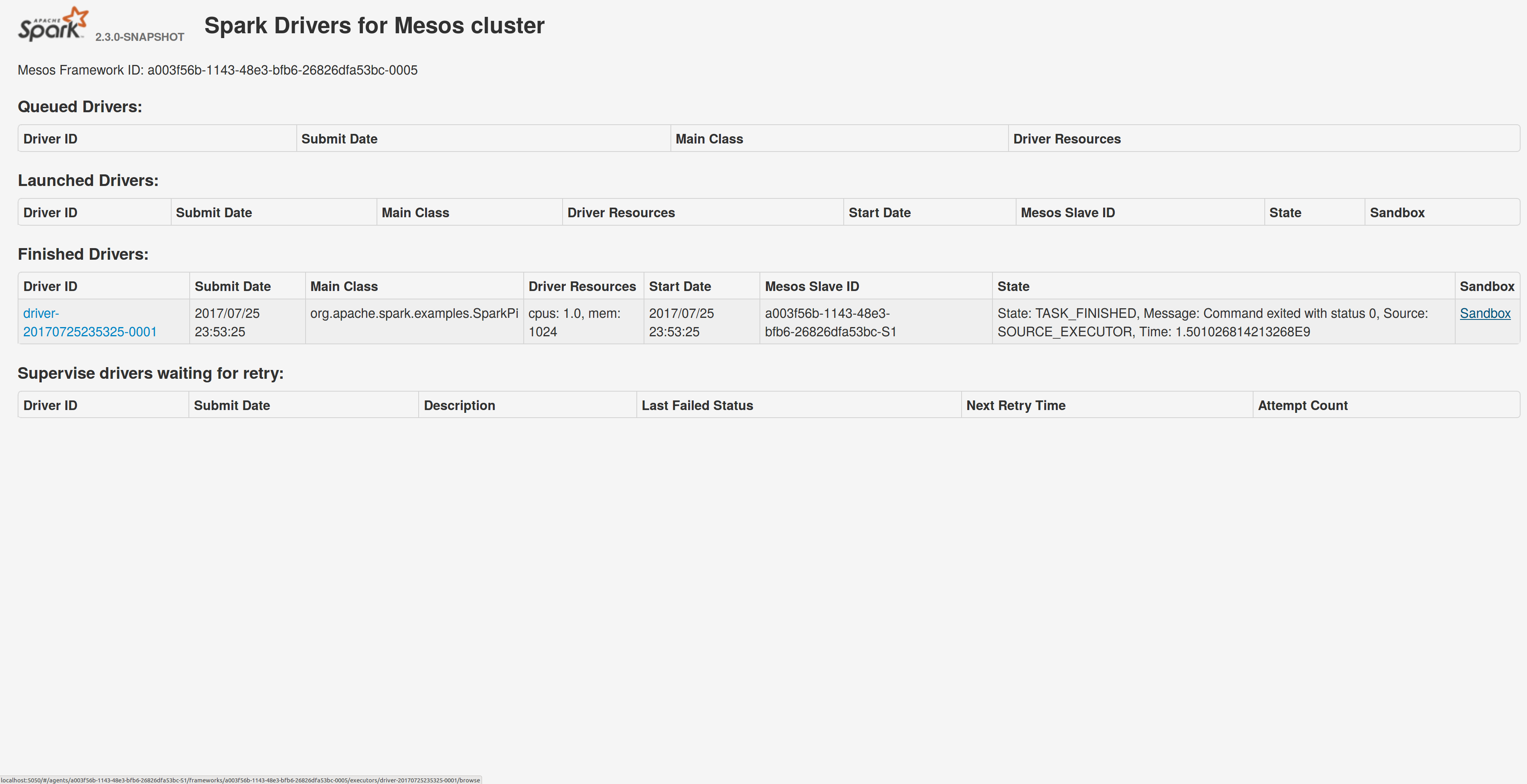 Redirection works as expected: 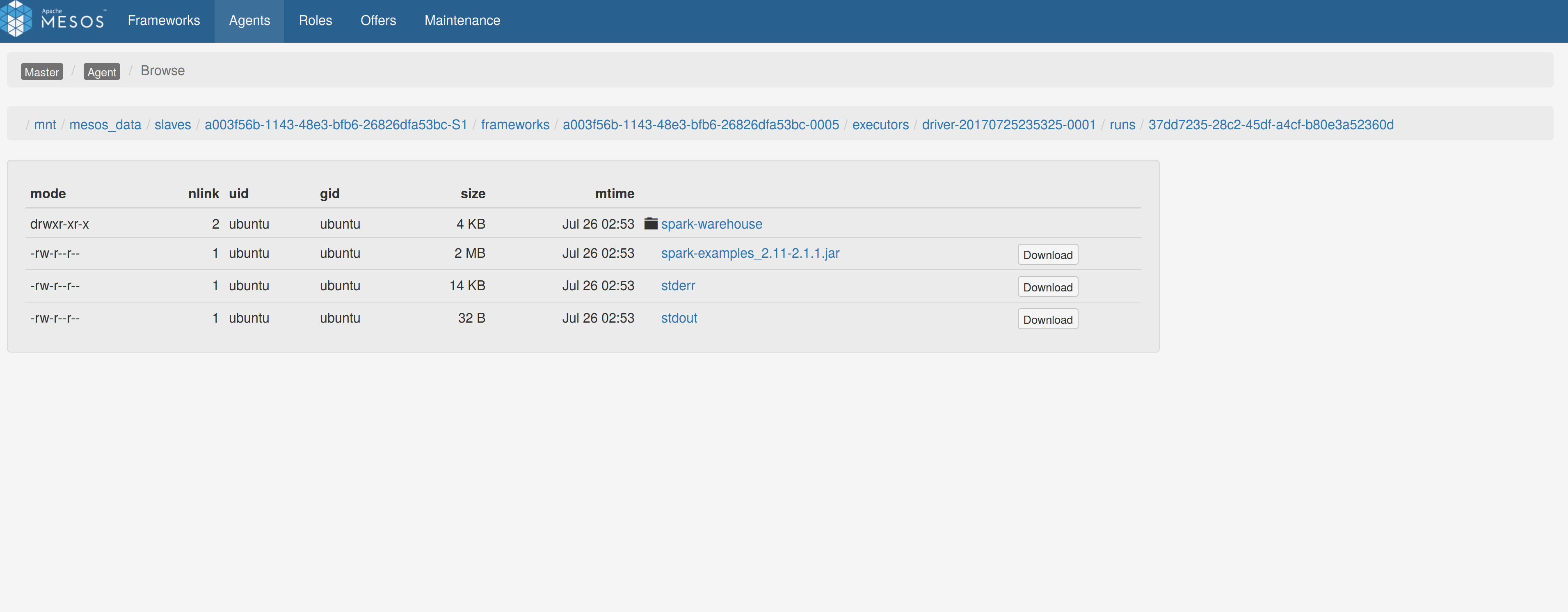 Author: Stavros Kontopoulos <st.kontopoulos@gmail.com> Closes #18528 from skonto/adds_the_sandbox_uri.
-
Xianyang Liu authored
## What changes were proposed in this pull request? We should reset numRecordsWritten to zero after DiskBlockObjectWriter.commitAndGet called. Because when `revertPartialWritesAndClose` be called, we decrease the written records in `ShuffleWriteMetrics` . However, we decreased the written records to zero, this should be wrong, we should only decreased the number reords after the last `commitAndGet` called. ## How was this patch tested? Modified existing test. Please review http://spark.apache.org/contributing.html before opening a pull request. Author: Xianyang Liu <xianyang.liu@intel.com> Closes #18830 from ConeyLiu/DiskBlockObjectWriter.
-
- Aug 06, 2017
-
-
Sean Owen authored
## What changes were proposed in this pull request? Remove duplicate test-jar:test spark-sql dependency from Hive module; move test-jar dependencies together logically. This generates a big warning at the start of the Maven build otherwise. ## How was this patch tested? Existing build. No functional changes here. Author: Sean Owen <sowen@cloudera.com> Closes #18858 from srowen/DupeSqlTestDep.
-
BartekH authored
I have discovered that "full_outer" name option is working in Spark 2.0, but it is not printed in exception. Please verify. ## What changes were proposed in this pull request? (Please fill in changes proposed in this fix) ## How was this patch tested? (Please explain how this patch was tested. E.g. unit tests, integration tests, manual tests) (If this patch involves UI changes, please attach a screenshot; otherwise, remove this) Please review http://spark.apache.org/contributing.html before opening a pull request. Author: BartekH <bartekhamielec@gmail.com> Closes #17985 from BartekH/patch-1.
-
actuaryzhang authored
## What changes were proposed in this pull request? Support offset in SparkR GLM #16699 Author: actuaryzhang <actuaryzhang10@gmail.com> Closes #18831 from actuaryzhang/sparkROffset.
-
Takeshi Yamamuro authored
## What changes were proposed in this pull request? This pr (follow-up of #18772) used `UnresolvedSubqueryColumnAliases` for `visitTableName` in `AstBuilder`, which is a new unresolved `LogicalPlan` implemented in #18185. ## How was this patch tested? Existing tests Author: Takeshi Yamamuro <yamamuro@apache.org> Closes #18857 from maropu/SPARK-20963-FOLLOWUP.
-
Yuming Wang authored
## What changes were proposed in this pull request? Since Spark 2.0.0, SET hive config commands do not pass the values to HiveClient, this PR point out user to set hive config before SparkSession is initialized when they try to set hive config. ## How was this patch tested? manual tests <img width="1637" alt="spark-set" src="https://user-images.githubusercontent.com/5399861/29001141-03f943ee-7ab3-11e7-8584-ba5a5e81f6ad.png"> Author: Yuming Wang <wgyumg@gmail.com> Closes #18769 from wangyum/SPARK-21574.
-
Felix Cheung authored
## What changes were proposed in this pull request? R version update ## How was this patch tested? AppVeyor Author: Felix Cheung <felixcheung_m@hotmail.com> Closes #18856 from felixcheung/rappveyorver.
-
vinodkc authored
## What changes were proposed in this pull request? In SQLContext.get(key,null) for a key that is not defined in the conf, and doesn't have a default value defined, throws a NPE. Int happens only when conf has a value converter Added null check on defaultValue inside SQLConf.getConfString to avoid calling entry.valueConverter(defaultValue) ## How was this patch tested? Added unit test Author: vinodkc <vinod.kc.in@gmail.com> Closes #18852 from vinodkc/br_Fix_SPARK-21588.
-
- Aug 05, 2017
-
-
Takeshi Yamamuro authored
## What changes were proposed in this pull request? This pr added parsing rules to support column aliases for join relations in FROM clause. This pr is a sub-task of #18079. ## How was this patch tested? Added tests in `AnalysisSuite`, `PlanParserSuite,` and `SQLQueryTestSuite`. Author: Takeshi Yamamuro <yamamuro@apache.org> Closes #18772 from maropu/SPARK-20963-2.
-
hzyaoqin authored
## What changes were proposed in this pull request? When we use `bin/spark-sql` command configuring `--conf spark.hadoop.foo=bar`, the `SparkSQLCliDriver` initializes an instance of hiveconf, it does not add `foo->bar` to it. this pr gets `spark.hadoop.*` properties from sysProps to this hiveconf ## How was this patch tested? UT Author: hzyaoqin <hzyaoqin@corp.netease.com> Author: Kent Yao <yaooqinn@hotmail.com> Closes #18668 from yaooqinn/SPARK-21451.
-
arodriguez authored
## What changes were proposed in this pull request? This PR includes the changes to make the string "errorifexists" also valid for ErrorIfExists save mode. ## How was this patch tested? Unit tests and manual tests Author: arodriguez <arodriguez@arodriguez.stratio> Closes #18844 from ardlema/SPARK-21640.
-
hyukjinkwon authored
[SPARK-21485][FOLLOWUP][SQL][DOCS] Describes examples and arguments separately, and note/since in SQL built-in function documentation ## What changes were proposed in this pull request? This PR proposes to separate `extended` into `examples` and `arguments` internally so that both can be separately documented and add `since` and `note` for additional information. For `since`, it looks users sometimes get confused by, up to my knowledge, missing version information. For example, see https://www.mail-archive.com/userspark.apache.org/msg64798.html For few good examples to check the built documentation, please see both: `from_json` - https://spark-test.github.io/sparksqldoc/#from_json `like` - https://spark-test.github.io/sparksqldoc/#like For `DESCRIBE FUNCTION`, `note` and `since` are added as below: ``` > DESCRIBE FUNCTION EXTENDED rlike; ... Extended Usage: Arguments: ... Examples: ... Note: Use LIKE to match with simple string pattern ``` ``` > DESCRIBE FUNCTION EXTENDED to_json; ... Examples: ... Since: 2.2.0 ``` For the complete documentation, see https://spark-test.github.io/sparksqldoc/ ## How was this patch tested? Manual tests and existing tests. Please see https://spark-test.github.io/sparksqldoc Jenkins tests are needed to double check Author: hyukjinkwon <gurwls223@gmail.com> Closes #18749 from HyukjinKwon/followup-sql-doc-gen.
-
hyukjinkwon authored
## What changes were proposed in this pull request? This PR proposes to close stale PRs, mostly the same instances with #18017 Closes #14085 - [SPARK-16408][SQL] SparkSQL Added file get Exception: is a directory … Closes #14239 - [SPARK-16593] [CORE] [WIP] Provide a pre-fetch mechanism to accelerate shuffle stage. Closes #14567 - [SPARK-16992][PYSPARK] Python Pep8 formatting and import reorganisation Closes #14579 - [SPARK-16921][PYSPARK] RDD/DataFrame persist()/cache() should return Python context managers Closes #14601 - [SPARK-13979][Core] Killed executor is re spawned without AWS key… Closes #14830 - [SPARK-16992][PYSPARK][DOCS] import sort and autopep8 on Pyspark examples Closes #14963 - [SPARK-16992][PYSPARK] Virtualenv for Pylint and pep8 in lint-python Closes #15227 - [SPARK-17655][SQL]Remove unused variables declarations and definations in a WholeStageCodeGened stage Closes #15240 - [SPARK-17556] [CORE] [SQL] Executor side broadcast for broadcast joins Closes #15405 - [SPARK-15917][CORE] Added support for number of executors in Standalone [WIP] Closes #16099 - [SPARK-18665][SQL] set statement state to "ERROR" after user cancel job Closes #16445 - [SPARK-19043][SQL]Make SparkSQLSessionManager more configurable Closes #16618 - [SPARK-14409][ML][WIP] Add RankingEvaluator Closes #16766 - [SPARK-19426][SQL] Custom coalesce for Dataset Closes #16832 - [SPARK-19490][SQL] ignore case sensitivity when filtering hive partition columns Closes #17052 - [SPARK-19690][SS] Join a streaming DataFrame with a batch DataFrame which has an aggregation may not work Closes #17267 - [SPARK-19926][PYSPARK] Make pyspark exception more user-friendly Closes #17371 - [SPARK-19903][PYSPARK][SS] window operator miss the `watermark` metadata of time column Closes #17401 - [SPARK-18364][YARN] Expose metrics for YarnShuffleService Closes #17519 - [SPARK-15352][Doc] follow-up: add configuration docs for topology-aware block replication Closes #17530 - [SPARK-5158] Access kerberized HDFS from Spark standalone Closes #17854 - [SPARK-20564][Deploy] Reduce massive executor failures when executor count is large (>2000) Closes #17979 - [SPARK-19320][MESOS][WIP]allow specifying a hard limit on number of gpus required in each spark executor when running on mesos Closes #18127 - [SPARK-6628][SQL][Branch-2.1] Fix ClassCastException when executing sql statement 'insert into' on hbase table Closes #18236 - [SPARK-21015] Check field name is not null and empty in GenericRowWit… Closes #18269 - [SPARK-21056][SQL] Use at most one spark job to list files in InMemoryFileIndex Closes #18328 - [SPARK-21121][SQL] Support changing storage level via the spark.sql.inMemoryColumnarStorage.level variable Closes #18354 - [SPARK-18016][SQL][CATALYST][BRANCH-2.1] Code Generation: Constant Pool Limit - Class Splitting Closes #18383 - [SPARK-21167][SS] Set kafka clientId while fetch messages Closes #18414 - [SPARK-21169] [core] Make sure to update application status to RUNNING if executors are accepted and RUNNING after recovery Closes #18432 - resolve com.esotericsoftware.kryo.KryoException Closes #18490 - [SPARK-21269][Core][WIP] Fix FetchFailedException when enable maxReqSizeShuffleToMem and KryoSerializer Closes #18585 - SPARK-21359 Closes #18609 - Spark SQL merge small files to big files Update InsertIntoHiveTable.scala Added: Closes #18308 - [SPARK-21099][Spark Core] INFO Log Message Using Incorrect Executor I… Closes #18599 - [SPARK-21372] spark writes one log file even I set the number of spark_rotate_log to 0 Closes #18619 - [SPARK-21397][BUILD]Maven shade plugin adding dependency-reduced-pom.xml to … Closes #18667 - Fix the simpleString used in error messages Closes #18782 - Branch 2.1 Added: Closes #17694 - [SPARK-12717][PYSPARK] Resolving race condition with pyspark broadcasts when using multiple threads Added: Closes #16456 - [SPARK-18994] clean up the local directories for application in future by annother thread Closes #18683 - [SPARK-21474][CORE] Make number of parallel fetches from a reducer configurable Closes #18690 - [SPARK-21334][CORE] Add metrics reporting service to External Shuffle Server Added: Closes #18827 - Merge pull request 1 from apache/master ## How was this patch tested? N/A Author: hyukjinkwon <gurwls223@gmail.com> Closes #18780 from HyukjinKwon/close-prs.
-
liuxian authored
## What changes were proposed in this pull request? create temporary view data as select * from values (1, 1), (1, 2), (2, 1), (2, 2), (3, 1), (3, 2) as data(a, b); `select 3, 4, sum(b) from data group by 1, 2;` `select 3 as c, 4 as d, sum(b) from data group by c, d;` When running these two cases, the following exception occurred: `Error in query: GROUP BY position 4 is not in select list (valid range is [1, 3]); line 1 pos 10` The cause of this failure: If an aggregateExpression is integer, after replaced with this aggregateExpression, the groupExpression still considered as an ordinal. The solution: This bug is due to re-entrance of an analyzed plan. We can solve it by using `resolveOperators` in `SubstituteUnresolvedOrdinals`. ## How was this patch tested? Added unit test case Author: liuxian <liu.xian3@zte.com.cn> Closes #18779 from 10110346/groupby.
-
Shixiong Zhu authored
## What changes were proposed in this pull request? This PR replaces #18623 to do some clean up. Closes #18623 ## How was this patch tested? Jenkins Author: Shixiong Zhu <shixiong@databricks.com> Author: Andrey Taptunov <taptunov@amazon.com> Closes #18848 from zsxwing/review-pr18623.
-
- Aug 04, 2017
-
-
Reynold Xin authored
## What changes were proposed in this pull request? OneRowRelation is the only plan that is a case object, which causes some issues with makeCopy using a 0-arg constructor. This patch changes it from a case object to a case class. This blocks SPARK-21619. ## How was this patch tested? Should be covered by existing test cases. Author: Reynold Xin <rxin@databricks.com> Closes #18839 from rxin/SPARK-21634.
-
Yuming Wang authored
## What changes were proposed in this pull request? Hive `pmod(3.13, 0)`: ```:sql hive> select pmod(3.13, 0); OK NULL Time taken: 2.514 seconds, Fetched: 1 row(s) hive> ``` Spark `mod(3.13, 0)`: ```:sql spark-sql> select mod(3.13, 0); NULL spark-sql> ``` But the Spark `pmod(3.13, 0)`: ```:sql spark-sql> select pmod(3.13, 0); 17/06/25 09:35:58 ERROR SparkSQLDriver: Failed in [select pmod(3.13, 0)] java.lang.NullPointerException at org.apache.spark.sql.catalyst.expressions.Pmod.pmod(arithmetic.scala:504) at org.apache.spark.sql.catalyst.expressions.Pmod.nullSafeEval(arithmetic.scala:432) at org.apache.spark.sql.catalyst.expressions.BinaryExpression.eval(Expression.scala:419) at org.apache.spark.sql.catalyst.expressions.UnaryExpression.eval(Expression.scala:323) ... ``` This PR make `pmod(number, 0)` to null. ## How was this patch tested? unit tests Author: Yuming Wang <wgyumg@gmail.com> Closes #18413 from wangyum/SPARK-21205.
-
Ajay Saini authored
## What changes were proposed in this pull request? Implemented UnaryTransformer in Python. ## How was this patch tested? This patch was tested by creating a MockUnaryTransformer class in the unit tests that extends UnaryTransformer and testing that the transform function produced correct output. Author: Ajay Saini <ajays725@gmail.com> Closes #18746 from ajaysaini725/AddPythonUnaryTransformer.
-
Andrew Ray authored
[SPARK-21330][SQL] Bad partitioning does not allow to read a JDBC table with extreme values on the partition column ## What changes were proposed in this pull request? An overflow of the difference of bounds on the partitioning column leads to no data being read. This patch checks for this overflow. ## How was this patch tested? New unit test. Author: Andrew Ray <ray.andrew@gmail.com> Closes #18800 from aray/SPARK-21330.
-
Dmitry Parfenchik authored
## What changes were proposed in this pull request? As described in JIRA ticket, History page is taking ~1min to load for cases when amount of jobs is 10k+. Most of the time is currently being spent on DOM manipulations and all additional costs implied by this (browser repaints and reflows). PR's goal is not to change any behavior but to optimize time of History UI rendering: 1. The most costly operation is setting `innerHTML` for `duration` column within a loop, which is [extremely unperformant](https://jsperf.com/jquery-append-vs-html-list-performance/24). [Refactoring ](https://github.com/criteo-forks/spark/commit/114943b21a730092aa3249b7a905b240bd46e531) this helped to get page load time **down to 10-15s** 2. Second big gain bringing page load time **down to 4s** was [was achieved](https://github.com/criteo-forks/spark/commit/f35fdcd5f129339fce75996e9242c88085a9b8ab) by detaching table's DOM before parsing it with DataTables jQuery plugin. 3. Another chunk of improvements ([1](https://github.com/criteo-forks/spark/commit/332b398db7eb3052484d436919185cb0b62b2385), [2](https://github.com/criteo-forks/spark/commit/0af596a547e3a1f2b594a83cbda1f6ef559de86b), [3](https://github.com/criteo-forks/spark/commit/235f164178a09e22306f05090ee1ff5f314a6710)) was focused on removing unnecessary DOM manipulations that in total contributed ~250ms to page load time. ## How was this patch tested? Tested by existing Selenium tests in `org.apache.spark.deploy.history.HistoryServerSuite`. Changes were also tested on Criteo's spark-2.1 fork with 20k+ number of rows in the table, reducing load time to 4s. Author: Dmitry Parfenchik <d.parfenchik@criteo.com> Author: Anna Savarin <a.savarin@criteo.com> Closes #18783 from 2ooom/history-ui-perf-fix-upstream-master.
-
- Aug 03, 2017
-
-
Christiam Camacho authored
## What changes were proposed in this pull request? Add missing import and missing parentheses to invoke `SparkSession::text()`. ## How was this patch tested? Built and the code for this application, ran jekyll locally per docs/README.md. Author: Christiam Camacho <camacho@ncbi.nlm.nih.gov> Closes #18795 from christiam/master.
-
louis lyu authored
## What changes were proposed in this pull request? In executor, toTaskFailedReason is converted to toTaskCommitDeniedReason to avoid the inconsistency of taskState. In JobProgressListener, add case TaskCommitDenied so that now the stage killed number is been incremented other than failed number. This pull request is picked up from: https://github.com/apache/spark/pull/18070 using commit: ff93ade0248baf3793ab55659042f9d7b8efbdef The case match for TaskCommitDenied is added incrementing the correct num of killed after pull/18070. ## How was this patch tested? Run a normal speculative job and check the Stage UI page, should have no failed displayed. Author: louis lyu <llyu@c02tk24rg8wl-lm.champ.corp.yahoo.com> Closes #18819 from nlyu/SPARK-20713.
-
Dilip Biswal authored
[SPARK-21599][SQL] Collecting column statistics for datasource tables may fail with java.util.NoSuchElementException ## What changes were proposed in this pull request? In case of datasource tables (when they are stored in non-hive compatible way) , the schema information is recorded as table properties in hive meta-store. The alterTableStats method needs to get the schema information from table properties for data source tables before recording the column level statistics. Currently, we don't get the correct schema information and fail with java.util.NoSuchElement exception. ## How was this patch tested? A new test case is added in StatisticsSuite. Author: Dilip Biswal <dbiswal@us.ibm.com> Closes #18804 from dilipbiswal/datasource_stats.
-
hyukjinkwon authored
## What changes were proposed in this pull request? This PR adds `map_values` and `map_keys` to R API. ```r > df <- createDataFrame(cbind(model = rownames(mtcars), mtcars)) > tmp <- mutate(df, v = create_map(df$model, df$cyl)) > head(select(tmp, map_keys(tmp$v))) ``` ``` map_keys(v) 1 Mazda RX4 2 Mazda RX4 Wag 3 Datsun 710 4 Hornet 4 Drive 5 Hornet Sportabout 6 Valiant ``` ```r > head(select(tmp, map_values(tmp$v))) ``` ``` map_values(v) 1 6 2 6 3 4 4 6 5 8 6 6 ``` ## How was this patch tested? Manual tests and unit tests in `R/pkg/tests/fulltests/test_sparkSQL.R` Author: hyukjinkwon <gurwls223@gmail.com> Closes #18809 from HyukjinKwon/map-keys-values-r. -
Chang chen authored
With SPARK-21592, removing source and target properties from maven-compiler-plugin lets IntelliJ IDEA use default Language level and Target byte code version which are 1.4. This change adds source, target and encoding properties back to fix this issue. As I test, it doesn't increase compile time. Author: Chang chen <baibaichen@gmail.com> Closes #18808 from baibaichen/feature/idea-fix.
-
zuotingbing authored
## What changes were proposed in this pull request? Error class name for log in several classes. such as: `2017-08-02 16:43:37,695 INFO CompositeService: Operation log root directory is created: /tmp/mr/operation_logs` `Operation log root directory is created ... ` is in `SessionManager.java` actually. ## How was this patch tested? manual tests Author: zuotingbing <zuo.tingbing9@zte.com.cn> Closes #18816 from zuotingbing/SPARK-21611.
-
zuotingbing authored
## What changes were proposed in this pull request? if the object extends Logging, i suggest to remove the var LOG which is useless. ## How was this patch tested? Exist tests Author: zuotingbing <zuo.tingbing9@zte.com.cn> Closes #18811 from zuotingbing/SPARK-21604.
-
Ayush Singh authored
[SPARK-21615][ML][MLLIB][DOCS] Fix broken redirect in collaborative filtering docs to databricks training repo ## What changes were proposed in this pull request? * Current [MLlib Collaborative Filtering tutorial](https://spark.apache.org/docs/latest/mllib-collaborative-filtering.html) points to broken links to old databricks website. * Databricks moved all their content to [git repo](https://github.com/databricks/spark-training) * Two links needs to be fixed, * [training exercises](https://databricks-training.s3.amazonaws.com/index.html) * [personalized movie recommendation with spark.mllib](https://databricks-training.s3.amazonaws.com/movie-recommendation-with-mllib.html) ## How was this patch tested? Generated docs locally Author: Ayush Singh <singhay@ccs.neu.edu> Closes #18821 from singhay/SPARK-21615.
-
- Aug 02, 2017
-
-
Shixiong Zhu authored
## What changes were proposed in this pull request? When the watermark is not a column of `dropDuplicates`, right now it will crash. This PR fixed this issue. ## How was this patch tested? The new unit test. Author: Shixiong Zhu <shixiong@databricks.com> Closes #18822 from zsxwing/SPARK-21546.
-
Marcelo Vanzin authored
The code was failing to account for some cases when setting up log redirection. For example, if a user redirected only stdout to a file, the launcher code would leave stderr without redirection, which could lead to child processes getting stuck because stderr wasn't being read. So detect cases where only one of the streams is redirected, and redirect the other stream to the log as appropriate. For the old "launch()" API, redirection of the unconfigured stream only happens if the user has explicitly requested for log redirection. Log redirection is on by default with "startApplication()". Most of the change is actually adding new unit tests to make sure the different cases work as expected. As part of that, I moved some tests that were in the core/ module to the launcher/ module instead, since they don't depend on spark-submit. Author: Marcelo Vanzin <vanzin@cloudera.com> Closes #18696 from vanzin/SPARK-21490.
-
Shixiong Zhu authored
## What changes were proposed in this pull request? This PR fixed a potential overflow issue in EventTimeStats. ## How was this patch tested? The new unit tests Author: Shixiong Zhu <shixiong@databricks.com> Closes #18803 from zsxwing/avg.
-
zero323 authored
## What changes were proposed in this pull request? Python API for Constrained Logistic Regression based on #17922 , thanks for the original contribution from zero323 . ## How was this patch tested? Unit tests. Author: zero323 <zero323@users.noreply.github.com> Author: Yanbo Liang <ybliang8@gmail.com> Closes #18759 from yanboliang/SPARK-20601.
-
- Aug 01, 2017
-
-
Dongjoon Hyun authored
## What changes were proposed in this pull request? Due to SI-8479, [SPARK-1093](https://issues.apache.org/jira/browse/SPARK-21578) introduced redundant [SparkContext constructors](https://github.com/apache/spark/blob/master/core/src/main/scala/org/apache/spark/SparkContext.scala#L148-L181). However, [SI-8479](https://issues.scala-lang.org/browse/SI-8479) is already fixed in Scala 2.10.5 and Scala 2.11.1. The real reason to provide this constructor is that Java code can access `SparkContext` directly. It's Scala behavior, SI-4278. So, this PR adds an explicit testsuite, `JavaSparkContextSuite` to prevent future regression, and fixes the outdate comment, too. ## How was this patch tested? Pass the Jenkins with a new test suite. Author: Dongjoon Hyun <dongjoon@apache.org> Closes #18778 from dongjoon-hyun/SPARK-21578.
-
gatorsmile authored
### What changes were proposed in this pull request? The original error message is pretty confusing. It is unable to tell which number is `number of partitions` and which one is the `RDD ID`. This PR is to improve the checkpoint checking. ### How was this patch tested? N/A Author: gatorsmile <gatorsmile@gmail.com> Closes #18796 from gatorsmile/improveErrMsgForCheckpoint.
-































