- Aug 09, 2017
-
-
Takeshi Yamamuro authored
## What changes were proposed in this pull request? This pr updated `lz4-java` to the latest (v1.4.0) and removed custom `LZ4BlockInputStream`. We currently use custom `LZ4BlockInputStream` to read concatenated byte stream in shuffle. But, this functionality has been implemented in the latest lz4-java (https://github.com/lz4/lz4-java/pull/105). So, we might update the latest to remove the custom `LZ4BlockInputStream`. Major diffs between the latest release and v1.3.0 in the master are as follows (https://github.com/lz4/lz4-java/compare/62f7547abb0819d1ca1e669645ee1a9d26cd60b0...6d4693f56253fcddfad7b441bb8d917b182efa2d); - fixed NPE in XXHashFactory similarly - Don't place resources in default package to support shading - Fixes ByteBuffer methods failing to apply arrayOffset() for array-backed - Try to load lz4-java from java.library.path, then fallback to bundled - Add ppc64le binary - Add s390x JNI binding - Add basic LZ4 Frame v1.5.0 support - enable aarch64 support for lz4-java - Allow unsafeInstance() for ppc64le archiecture - Add unsafeInstance support for AArch64 - Support 64-bit JNI build on Solaris - Avoid over-allocating a buffer - Allow EndMark to be incompressible for LZ4FrameInputStream. - Concat byte stream ## How was this patch tested? Existing tests. Author: Takeshi Yamamuro <yamamuro@apache.org> Closes #18883 from maropu/SPARK-21276.
-
vinodkc authored
## What changes were proposed in this pull request? Resources in Core - SparkSubmitArguments.scala, Spark-launcher - AbstractCommandBuilder.java, resource-managers- YARN - Client.scala are released ## How was this patch tested? No new test cases added, Unit test have been passed Author: vinodkc <vinod.kc.in@gmail.com> Closes #18880 from vinodkc/br_fixresouceleak.
-
10087686 authored
[SPARK-21663][TESTS] test("remote fetch below max RPC message size") should call masterTracker.stop() in MapOutputTrackerSuite Signed-off-by: 10087686 <wang.jiaochunzte.com.cn> ## What changes were proposed in this pull request? After Unit tests end,there should be call masterTracker.stop() to free resource; (Please fill in changes proposed in this fix) ## How was this patch tested? Run Unit tests; (Please explain how this patch was tested. E.g. unit tests, integration tests, manual tests) (If this patch involves UI changes, please attach a screenshot; otherwise, remove this) Please review http://spark.apache.org/contributing.html before opening a pull request. Author: 10087686 <wang.jiaochun@zte.com.cn> Closes #18867 from wangjiaochun/mapout. -
WeichenXu authored
## What changes were proposed in this pull request? Update breeze to 0.13.1 for an emergency bugfix in strong wolfe line search https://github.com/scalanlp/breeze/pull/651 ## How was this patch tested? N/A Author: WeichenXu <WeichenXu123@outlook.com> Closes #18797 from WeichenXu123/update-breeze.
-
Anderson Osagie authored
## What changes were proposed in this pull request? Currently, each application and each worker creates their own proxy servlet. Each proxy servlet is backed by its own HTTP client and a relatively large number of selector threads. This is excessive but was fixed (to an extent) by https://github.com/apache/spark/pull/18437. However, a single HTTP client (backed by a single selector thread) should be enough to handle all proxy requests. This PR creates a single proxy servlet no matter how many applications and workers there are. ## How was this patch tested? . The unit tests for rewriting proxied locations and headers were updated. I then spun up a 100 node cluster to ensure that proxy'ing worked correctly jiangxb1987 Please let me know if there's anything else I can do to help push this thru. Thanks! Author: Anderson Osagie <osagie@gmail.com> Closes #18499 from aosagie/fix/minimize-proxy-threads.
-
pgandhi authored
The executor tab on Spark UI page shows task as completed when an executor process that is running that task is killed using the kill command. Added the case ExecutorLostFailure which was previously not there, thus, the default case would be executed in which case, task would be marked as completed. This case will consider all those cases where executor connection to Spark Driver was lost due to killing the executor process, network connection etc. ## How was this patch tested? Manually Tested the fix by observing the UI change before and after. Before: <img width="1398" alt="screen shot-before" src="https://user-images.githubusercontent.com/22228190/28482929-571c9cea-6e30-11e7-93dd-728de5cdea95.png"> After: <img width="1385" alt="screen shot-after" src="https://user-images.githubusercontent.com/22228190/28482964-8649f5ee-6e30-11e7-91bd-2eb2089c61cc.png"> Please review http://spark.apache.org/contributing.html before opening a pull request. Author: pgandhi <pgandhi@yahoo-inc.com> Author: pgandhi999 <parthkgandhi9@gmail.com> Closes #18707 from pgandhi999/master.
-
Xingbo Jiang authored
## What changes were proposed in this pull request? Window rangeBetween() API should allow literal boundary, that means, the window range frame can calculate frame of double/date/timestamp. Example of the use case can be: ``` SELECT val_timestamp, cate, avg(val_timestamp) OVER(PARTITION BY cate ORDER BY val_timestamp RANGE BETWEEN CURRENT ROW AND interval 23 days 4 hours FOLLOWING) FROM testData ``` This PR refactors the Window `rangeBetween` and `rowsBetween` API, while the legacy user code should still be valid. ## How was this patch tested? Add new test cases both in `DataFrameWindowFunctionsSuite` and in `window.sql`. Author: Xingbo Jiang <xingbo.jiang@databricks.com> Closes #18814 from jiangxb1987/literal-boundary.
-
- Aug 08, 2017
-
-
Shixiong Zhu authored
## What changes were proposed in this pull request? When I was investigating a flaky test, I realized that many places don't check the return value of `HDFSMetadataLog.get(batchId: Long): Option[T]`. When a batch is supposed to be there, the caller just ignores None rather than throwing an error. If some bug causes a query doesn't generate a batch metadata file, this behavior will hide it and allow the query continuing to run and finally delete metadata logs and make it hard to debug. This PR ensures that places calling HDFSMetadataLog.get always check the return value. ## How was this patch tested? Jenkins Author: Shixiong Zhu <shixiong@databricks.com> Closes #18799 from zsxwing/SPARK-21596.
-
Sean Owen authored
## What changes were proposed in this pull request? Taking over https://github.com/apache/spark/pull/18789 ; Closes #18789 Update Jackson to 2.6.7 uniformly, and some components to 2.6.7.1, to get some fixes and prep for Scala 2.12 ## How was this patch tested? Existing tests Author: Sean Owen <sowen@cloudera.com> Closes #18881 from srowen/SPARK-20433.
-
Marcelo Vanzin authored
Author: Marcelo Vanzin <vanzin@cloudera.com> Closes #18886 from vanzin/SPARK-21671.
-
Marcelo Vanzin authored
This change adds an in-memory implementation of KVStore that can be used by the live UI. The implementation is not fully optimized, neither for speed nor space, but should be fast enough for using in the listener bus. Author: Marcelo Vanzin <vanzin@cloudera.com> Closes #18395 from vanzin/SPARK-20655.
-
hyukjinkwon authored
## What changes were proposed in this pull request? This PR proposes to use https://rversions.r-pkg.org/r-release-win instead of https://rversions.r-pkg.org/r-release to check R's version for Windows correctly. We met a syncing problem with Windows release (see #15709) before. To cut this short, it was ... - 3.3.2 release was released but not for Windows for few hours. - `https://rversions.r-pkg.org/r-release` returns the latest as 3.3.2 and the download link for 3.3.1 becomes `windows/base/old` by our script - 3.3.2 release for WIndows yet - 3.3.1 is still not in `windows/base/old` but `windows/base` as the latest - Failed to download with `windows/base/old` link and builds were broken I believe this problem is not only what we met. Please see https://github.com/krlmlr/r-appveyor/commit/01ce943929993bbf27facd2cdc20ae2e03808eb4 and also this `r-release-win` API came out between 3.3.1 and 3.3.2 (assuming to deal with this issue), please see `https://github.com/metacran/rversions.app/issues/2`. Using this API will prevent the problem although it looks quite rare assuming from the commit logs in https://github.com/metacran/rversions.app/commits/master. After 3.3.2, both `r-release-win` and `r-release` are being updated together. ## How was this patch tested? AppVeyor tests. Author: hyukjinkwon <gurwls223@gmail.com> Closes #18859 from HyukjinKwon/use-reliable-link.
-
Liang-Chi Hsieh authored
## What changes were proposed in this pull request? If we create a type alias for a type workable with Dataset, the type alias doesn't work with Dataset. A reproducible case looks like: object C { type TwoInt = (Int, Int) def tupleTypeAlias: TwoInt = (1, 1) } Seq(1).toDS().map(_ => ("", C.tupleTypeAlias)) It throws an exception like: type T1 is not a class scala.ScalaReflectionException: type T1 is not a class at scala.reflect.api.Symbols$SymbolApi$class.asClass(Symbols.scala:275) ... This patch accesses the dealias of type in many places in `ScalaReflection` to fix it. ## How was this patch tested? Added test case. Author: Liang-Chi Hsieh <viirya@gmail.com> Closes #18813 from viirya/SPARK-21567. -
Marcos P. Sanchez authored
## What changes were proposed in this pull request? This commit adds a new argument for IllegalArgumentException message. This recent commit added the argument: [https://github.com/apache/spark/commit/dcac1d57f0fd05605edf596c303546d83062a352](https://github.com/apache/spark/commit/dcac1d57f0fd05605edf596c303546d83062a352) ## How was this patch tested? Unit test have been passed Please review http://spark.apache.org/contributing.html before opening a pull request. Author: Marcos P. Sanchez <mpenate@stratio.com> Closes #18862 from mpenate/feature/exception-errorifexists.
-
- Aug 07, 2017
-
-
Yanbo Liang authored
## What changes were proposed in this pull request? PySpark GLR ```model.summary``` should return a printable representation by calling Scala ```toString```. ## How was this patch tested? ``` from pyspark.ml.regression import GeneralizedLinearRegression dataset = spark.read.format("libsvm").load("data/mllib/sample_linear_regression_data.txt") glr = GeneralizedLinearRegression(family="gaussian", link="identity", maxIter=10, regParam=0.3) model = glr.fit(dataset) model.summary ``` Before this PR:  After this PR: 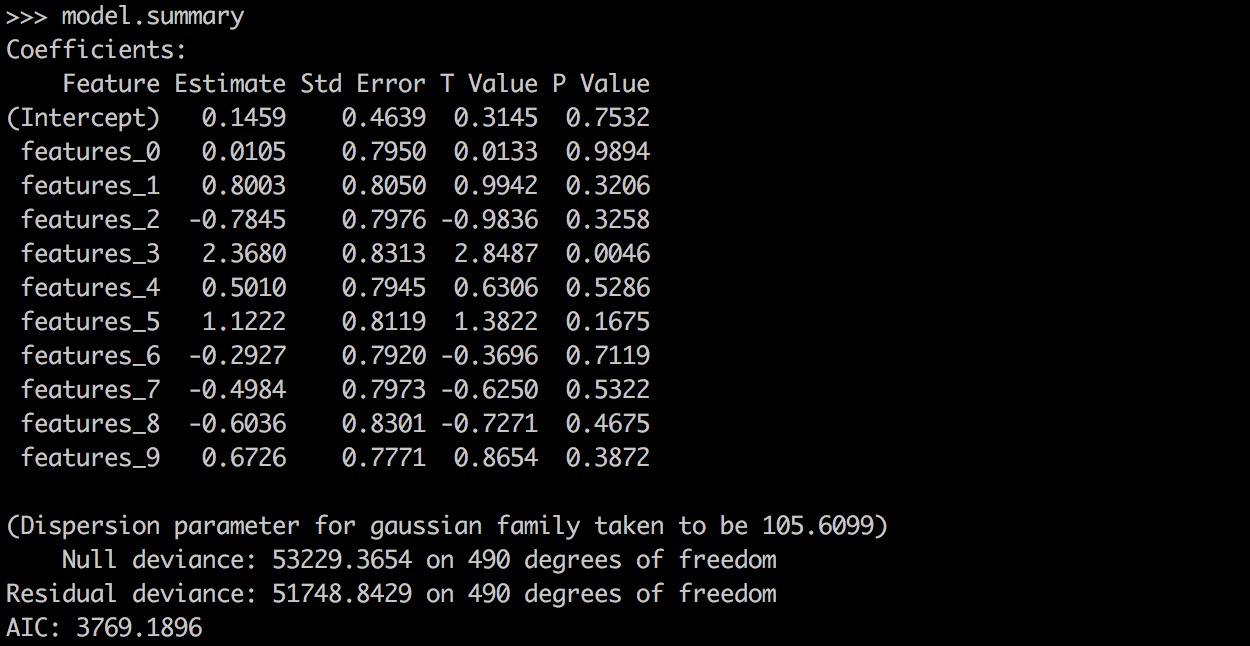 Author: Yanbo Liang <ybliang8@gmail.com> Closes #18870 from yanboliang/spark-19270. -
Ajay Saini authored
## What changes were proposed in this pull request? Added DefaultParamsWriteable, DefaultParamsReadable, DefaultParamsWriter, and DefaultParamsReader to Python to support Python-only persistence of Json-serializable parameters. ## How was this patch tested? Instantiated an estimator with Json-serializable parameters (ex. LogisticRegression), saved it using the added helper functions, and loaded it back, and compared it to the original instance to make sure it is the same. This test was both done in the Python REPL and implemented in the unit tests. Note to reviewers: there are a few excess comments that I left in the code for clarity but will remove before the code is merged to master. Author: Ajay Saini <ajays725@gmail.com> Closes #18742 from ajaysaini725/PythonPersistenceHelperFunctions.
-
gatorsmile authored
[SPARK-21648][SQL] Fix confusing assert failure in JDBC source when parallel fetching parameters are not properly provided. ### What changes were proposed in this pull request? ```SQL CREATE TABLE mytesttable1 USING org.apache.spark.sql.jdbc OPTIONS ( url 'jdbc:mysql://${jdbcHostname}:${jdbcPort}/${jdbcDatabase}?user=${jdbcUsername}&password=${jdbcPassword}', dbtable 'mytesttable1', paritionColumn 'state_id', lowerBound '0', upperBound '52', numPartitions '53', fetchSize '10000' ) ``` The above option name `paritionColumn` is wrong. That mean, users did not provide the value for `partitionColumn`. In such case, users hit a confusing error. ``` AssertionError: assertion failed java.lang.AssertionError: assertion failed at scala.Predef$.assert(Predef.scala:156) at org.apache.spark.sql.execution.datasources.jdbc.JdbcRelationProvider.createRelation(JdbcRelationProvider.scala:39) at org.apache.spark.sql.execution.datasources.DataSource.resolveRelation(DataSource.scala:312) ``` ### How was this patch tested? Added a test case Author: gatorsmile <gatorsmile@gmail.com> Closes #18864 from gatorsmile/jdbcPartCol. -
Jose Torres authored
## What changes were proposed in this pull request? Propagate metadata in attribute replacement during streaming execution. This is necessary for EventTimeWatermarks consuming replaced attributes. ## How was this patch tested? new unit test, which was verified to fail before the fix Author: Jose Torres <joseph-torres@databricks.com> Closes #18840 from joseph-torres/SPARK-21565.
-
Mac authored
## What changes were proposed in this pull request? Enhanced some existing documentation Please review http://spark.apache.org/contributing.html before opening a pull request. Author: Mac <maclockard@gmail.com> Closes #18710 from maclockard/maclockard-patch-1.
-
Xiao Li authored
### What changes were proposed in this pull request? author: BoleynSu closes https://github.com/apache/spark/pull/18836 ```Scala val df = Seq((1, 1)).toDF("i", "j") df.createOrReplaceTempView("T") withSQLConf(SQLConf.AUTO_BROADCASTJOIN_THRESHOLD.key -> "-1") { sql("select * from (select a.i from T a cross join T t where t.i = a.i) as t1 " + "cross join T t2 where t2.i = t1.i").explain(true) } ``` The above code could cause the following exception: ``` SortMergeJoinExec should not take Cross as the JoinType java.lang.IllegalArgumentException: SortMergeJoinExec should not take Cross as the JoinType at org.apache.spark.sql.execution.joins.SortMergeJoinExec.outputOrdering(SortMergeJoinExec.scala:100) ``` Our SortMergeJoinExec supports CROSS. We should not hit such an exception. This PR is to fix the issue. ### How was this patch tested? Modified the two existing test cases. Author: Xiao Li <gatorsmile@gmail.com> Author: Boleyn Su <boleyn.su@gmail.com> Closes #18863 from gatorsmile/pr-18836.
-
zhoukang authored
## What changes were proposed in this pull request? **For moudle below:** common/network-common streaming sql/core sql/catalyst **tests.jar will install or deploy twice.Like:** `[DEBUG] Installing org.apache.spark:spark-streaming_2.11/maven-metadata.xml to /home/mi/.m2/repository/org/apache/spark/spark-streaming_2.11/maven-metadata-local.xml [INFO] Installing /home/mi/Work/Spark/scala2.11/spark/streaming/target/spark-streaming_2.11-2.1.0-mdh2.1.0.1-SNAPSHOT-tests.jar to /home/mi/.m2/repository/org/apache/spark/spark-streaming_2.11/2.1.0-mdh2.1.0.1-SNAPSHOT/spark-streaming_2.11-2.1.0-mdh2.1.0.1-SNAPSHOT-tests.jar [DEBUG] Skipped re-installing /home/mi/Work/Spark/scala2.11/spark/streaming/target/spark-streaming_2.11-2.1.0-mdh2.1.0.1-SNAPSHOT-tests.jar to /home/mi/.m2/repository/org/apache/spark/spark-streaming_2.11/2.1.0-mdh2.1.0.1-SNAPSHOT/spark-streaming_2.11-2.1.0-mdh2.1.0.1-SNAPSHOT-tests.jar, seems unchanged` **The reason is below:** `[DEBUG] (f) artifact = org.apache.spark:spark-streaming_2.11:jar:2.1.0-mdh2.1.0.1-SNAPSHOT [DEBUG] (f) attachedArtifacts = [org.apache.spark:spark-streaming_2.11:test-jar:tests:2.1.0-mdh2.1.0.1-SNAPSHOT, org.apache.spark:spark-streaming_2.11:jar:tests:2.1.0-mdh2.1.0.1-SNAPSHOT, org.apache.spark:spark -streaming_2.11:java-source:sources:2.1.0-mdh2.1.0.1-SNAPSHOT, org.apache.spark:spark-streaming_2.11:java-source:test-sources:2.1.0-mdh2.1.0.1-SNAPSHOT, org.apache.spark:spark-streaming_2.11:javadoc:javadoc:2.1.0 -mdh2.1.0.1-SNAPSHOT]` when executing 'mvn deploy' to nexus during release.I will fail since release nexus can not be overrided. ## How was this patch tested? Execute 'mvn clean install -Pyarn -Phadoop-2.6 -Phadoop-provided -DskipTests' Author: zhoukang <zhoukang199191@gmail.com> Closes #18745 from caneGuy/zhoukang/fix-installtwice.
-
Peng Meng authored
## What changes were proposed in this pull request? comments of parentStats in RF are wrong. parentStats is not only used for the first iteration, it is used with all the iteration for unordered features. ## How was this patch tested? Author: Peng Meng <peng.meng@intel.com> Closes #18832 from mpjlu/fixRFDoc.
-
Stavros Kontopoulos authored
## What changes were proposed in this pull request? Adds a sandbox link per driver in the dispatcher ui with minimal changes after a bug was fixed here: https://issues.apache.org/jira/browse/MESOS-4992 The sandbox uri has the following format: http://<proxy_uri>/#/slaves/\<agent-id\>/ frameworks/ \<scheduler-id\>/executors/\<driver-id\>/browse For dc/os the proxy uri is <dc/os uri>/mesos. For the dc/os deployment scenario and to make things easier I introduced a new config property named `spark.mesos.proxy.baseURL` which should be passed to the dispatcher when launched using --conf. If no such configuration is detected then no sandbox uri is depicted, and there is an empty column with a header (this can be changed so nothing is shown). Within dc/os the base url must be a property for the dispatcher that we should add in the future here: https://github.com/mesosphere/universe/blob/9e7c909c3b8680eeb0494f2a58d5746e3bab18c1/repo/packages/S/spark/26/config.json It is not easy to detect in different environments what is that uri so user should pass it. ## How was this patch tested? Tested with the mesos test suite here: https://github.com/typesafehub/mesos-spark-integration-tests. Attached image shows the ui modification where the sandbox header is added.  Tested the uri redirection the way it was suggested here: https://issues.apache.org/jira/browse/MESOS-4992 Built mesos 1.4 from the master branch and started the mesos dispatcher with the command: `./sbin/start-mesos-dispatcher.sh --conf spark.mesos.proxy.baseURL=http://localhost:5050 -m mesos://127.0.0.1:5050` Run a spark example: `./bin/spark-submit --class org.apache.spark.examples.SparkPi --master mesos://10.10.1.79:7078 --deploy-mode cluster --executor-memory 2G --total-executor-cores 2 http://<path>/spark-examples_2.11-2.1.1.jar 10` Sandbox uri is shown at the bottom of the page:  Redirection works as expected:  Author: Stavros Kontopoulos <st.kontopoulos@gmail.com> Closes #18528 from skonto/adds_the_sandbox_uri.
-
Xianyang Liu authored
## What changes were proposed in this pull request? We should reset numRecordsWritten to zero after DiskBlockObjectWriter.commitAndGet called. Because when `revertPartialWritesAndClose` be called, we decrease the written records in `ShuffleWriteMetrics` . However, we decreased the written records to zero, this should be wrong, we should only decreased the number reords after the last `commitAndGet` called. ## How was this patch tested? Modified existing test. Please review http://spark.apache.org/contributing.html before opening a pull request. Author: Xianyang Liu <xianyang.liu@intel.com> Closes #18830 from ConeyLiu/DiskBlockObjectWriter.
-
- Aug 06, 2017
-
-
Sean Owen authored
## What changes were proposed in this pull request? Remove duplicate test-jar:test spark-sql dependency from Hive module; move test-jar dependencies together logically. This generates a big warning at the start of the Maven build otherwise. ## How was this patch tested? Existing build. No functional changes here. Author: Sean Owen <sowen@cloudera.com> Closes #18858 from srowen/DupeSqlTestDep.
-
BartekH authored
I have discovered that "full_outer" name option is working in Spark 2.0, but it is not printed in exception. Please verify. ## What changes were proposed in this pull request? (Please fill in changes proposed in this fix) ## How was this patch tested? (Please explain how this patch was tested. E.g. unit tests, integration tests, manual tests) (If this patch involves UI changes, please attach a screenshot; otherwise, remove this) Please review http://spark.apache.org/contributing.html before opening a pull request. Author: BartekH <bartekhamielec@gmail.com> Closes #17985 from BartekH/patch-1.
-
actuaryzhang authored
## What changes were proposed in this pull request? Support offset in SparkR GLM #16699 Author: actuaryzhang <actuaryzhang10@gmail.com> Closes #18831 from actuaryzhang/sparkROffset.
-
Takeshi Yamamuro authored
## What changes were proposed in this pull request? This pr (follow-up of #18772) used `UnresolvedSubqueryColumnAliases` for `visitTableName` in `AstBuilder`, which is a new unresolved `LogicalPlan` implemented in #18185. ## How was this patch tested? Existing tests Author: Takeshi Yamamuro <yamamuro@apache.org> Closes #18857 from maropu/SPARK-20963-FOLLOWUP.
-
Yuming Wang authored
## What changes were proposed in this pull request? Since Spark 2.0.0, SET hive config commands do not pass the values to HiveClient, this PR point out user to set hive config before SparkSession is initialized when they try to set hive config. ## How was this patch tested? manual tests <img width="1637" alt="spark-set" src="https://user-images.githubusercontent.com/5399861/29001141-03f943ee-7ab3-11e7-8584-ba5a5e81f6ad.png"> Author: Yuming Wang <wgyumg@gmail.com> Closes #18769 from wangyum/SPARK-21574.
-
Felix Cheung authored
## What changes were proposed in this pull request? R version update ## How was this patch tested? AppVeyor Author: Felix Cheung <felixcheung_m@hotmail.com> Closes #18856 from felixcheung/rappveyorver.
-
vinodkc authored
## What changes were proposed in this pull request? In SQLContext.get(key,null) for a key that is not defined in the conf, and doesn't have a default value defined, throws a NPE. Int happens only when conf has a value converter Added null check on defaultValue inside SQLConf.getConfString to avoid calling entry.valueConverter(defaultValue) ## How was this patch tested? Added unit test Author: vinodkc <vinod.kc.in@gmail.com> Closes #18852 from vinodkc/br_Fix_SPARK-21588.
-
- Aug 05, 2017
-
-
Takeshi Yamamuro authored
## What changes were proposed in this pull request? This pr added parsing rules to support column aliases for join relations in FROM clause. This pr is a sub-task of #18079. ## How was this patch tested? Added tests in `AnalysisSuite`, `PlanParserSuite,` and `SQLQueryTestSuite`. Author: Takeshi Yamamuro <yamamuro@apache.org> Closes #18772 from maropu/SPARK-20963-2.
-
hzyaoqin authored
## What changes were proposed in this pull request? When we use `bin/spark-sql` command configuring `--conf spark.hadoop.foo=bar`, the `SparkSQLCliDriver` initializes an instance of hiveconf, it does not add `foo->bar` to it. this pr gets `spark.hadoop.*` properties from sysProps to this hiveconf ## How was this patch tested? UT Author: hzyaoqin <hzyaoqin@corp.netease.com> Author: Kent Yao <yaooqinn@hotmail.com> Closes #18668 from yaooqinn/SPARK-21451.
-
arodriguez authored
## What changes were proposed in this pull request? This PR includes the changes to make the string "errorifexists" also valid for ErrorIfExists save mode. ## How was this patch tested? Unit tests and manual tests Author: arodriguez <arodriguez@arodriguez.stratio> Closes #18844 from ardlema/SPARK-21640.
-
hyukjinkwon authored
[SPARK-21485][FOLLOWUP][SQL][DOCS] Describes examples and arguments separately, and note/since in SQL built-in function documentation ## What changes were proposed in this pull request? This PR proposes to separate `extended` into `examples` and `arguments` internally so that both can be separately documented and add `since` and `note` for additional information. For `since`, it looks users sometimes get confused by, up to my knowledge, missing version information. For example, see https://www.mail-archive.com/userspark.apache.org/msg64798.html For few good examples to check the built documentation, please see both: `from_json` - https://spark-test.github.io/sparksqldoc/#from_json `like` - https://spark-test.github.io/sparksqldoc/#like For `DESCRIBE FUNCTION`, `note` and `since` are added as below: ``` > DESCRIBE FUNCTION EXTENDED rlike; ... Extended Usage: Arguments: ... Examples: ... Note: Use LIKE to match with simple string pattern ``` ``` > DESCRIBE FUNCTION EXTENDED to_json; ... Examples: ... Since: 2.2.0 ``` For the complete documentation, see https://spark-test.github.io/sparksqldoc/ ## How was this patch tested? Manual tests and existing tests. Please see https://spark-test.github.io/sparksqldoc Jenkins tests are needed to double check Author: hyukjinkwon <gurwls223@gmail.com> Closes #18749 from HyukjinKwon/followup-sql-doc-gen.
-
hyukjinkwon authored
## What changes were proposed in this pull request? This PR proposes to close stale PRs, mostly the same instances with #18017 Closes #14085 - [SPARK-16408][SQL] SparkSQL Added file get Exception: is a directory … Closes #14239 - [SPARK-16593] [CORE] [WIP] Provide a pre-fetch mechanism to accelerate shuffle stage. Closes #14567 - [SPARK-16992][PYSPARK] Python Pep8 formatting and import reorganisation Closes #14579 - [SPARK-16921][PYSPARK] RDD/DataFrame persist()/cache() should return Python context managers Closes #14601 - [SPARK-13979][Core] Killed executor is re spawned without AWS key… Closes #14830 - [SPARK-16992][PYSPARK][DOCS] import sort and autopep8 on Pyspark examples Closes #14963 - [SPARK-16992][PYSPARK] Virtualenv for Pylint and pep8 in lint-python Closes #15227 - [SPARK-17655][SQL]Remove unused variables declarations and definations in a WholeStageCodeGened stage Closes #15240 - [SPARK-17556] [CORE] [SQL] Executor side broadcast for broadcast joins Closes #15405 - [SPARK-15917][CORE] Added support for number of executors in Standalone [WIP] Closes #16099 - [SPARK-18665][SQL] set statement state to "ERROR" after user cancel job Closes #16445 - [SPARK-19043][SQL]Make SparkSQLSessionManager more configurable Closes #16618 - [SPARK-14409][ML][WIP] Add RankingEvaluator Closes #16766 - [SPARK-19426][SQL] Custom coalesce for Dataset Closes #16832 - [SPARK-19490][SQL] ignore case sensitivity when filtering hive partition columns Closes #17052 - [SPARK-19690][SS] Join a streaming DataFrame with a batch DataFrame which has an aggregation may not work Closes #17267 - [SPARK-19926][PYSPARK] Make pyspark exception more user-friendly Closes #17371 - [SPARK-19903][PYSPARK][SS] window operator miss the `watermark` metadata of time column Closes #17401 - [SPARK-18364][YARN] Expose metrics for YarnShuffleService Closes #17519 - [SPARK-15352][Doc] follow-up: add configuration docs for topology-aware block replication Closes #17530 - [SPARK-5158] Access kerberized HDFS from Spark standalone Closes #17854 - [SPARK-20564][Deploy] Reduce massive executor failures when executor count is large (>2000) Closes #17979 - [SPARK-19320][MESOS][WIP]allow specifying a hard limit on number of gpus required in each spark executor when running on mesos Closes #18127 - [SPARK-6628][SQL][Branch-2.1] Fix ClassCastException when executing sql statement 'insert into' on hbase table Closes #18236 - [SPARK-21015] Check field name is not null and empty in GenericRowWit… Closes #18269 - [SPARK-21056][SQL] Use at most one spark job to list files in InMemoryFileIndex Closes #18328 - [SPARK-21121][SQL] Support changing storage level via the spark.sql.inMemoryColumnarStorage.level variable Closes #18354 - [SPARK-18016][SQL][CATALYST][BRANCH-2.1] Code Generation: Constant Pool Limit - Class Splitting Closes #18383 - [SPARK-21167][SS] Set kafka clientId while fetch messages Closes #18414 - [SPARK-21169] [core] Make sure to update application status to RUNNING if executors are accepted and RUNNING after recovery Closes #18432 - resolve com.esotericsoftware.kryo.KryoException Closes #18490 - [SPARK-21269][Core][WIP] Fix FetchFailedException when enable maxReqSizeShuffleToMem and KryoSerializer Closes #18585 - SPARK-21359 Closes #18609 - Spark SQL merge small files to big files Update InsertIntoHiveTable.scala Added: Closes #18308 - [SPARK-21099][Spark Core] INFO Log Message Using Incorrect Executor I… Closes #18599 - [SPARK-21372] spark writes one log file even I set the number of spark_rotate_log to 0 Closes #18619 - [SPARK-21397][BUILD]Maven shade plugin adding dependency-reduced-pom.xml to … Closes #18667 - Fix the simpleString used in error messages Closes #18782 - Branch 2.1 Added: Closes #17694 - [SPARK-12717][PYSPARK] Resolving race condition with pyspark broadcasts when using multiple threads Added: Closes #16456 - [SPARK-18994] clean up the local directories for application in future by annother thread Closes #18683 - [SPARK-21474][CORE] Make number of parallel fetches from a reducer configurable Closes #18690 - [SPARK-21334][CORE] Add metrics reporting service to External Shuffle Server Added: Closes #18827 - Merge pull request 1 from apache/master ## How was this patch tested? N/A Author: hyukjinkwon <gurwls223@gmail.com> Closes #18780 from HyukjinKwon/close-prs.
-
liuxian authored
## What changes were proposed in this pull request? create temporary view data as select * from values (1, 1), (1, 2), (2, 1), (2, 2), (3, 1), (3, 2) as data(a, b); `select 3, 4, sum(b) from data group by 1, 2;` `select 3 as c, 4 as d, sum(b) from data group by c, d;` When running these two cases, the following exception occurred: `Error in query: GROUP BY position 4 is not in select list (valid range is [1, 3]); line 1 pos 10` The cause of this failure: If an aggregateExpression is integer, after replaced with this aggregateExpression, the groupExpression still considered as an ordinal. The solution: This bug is due to re-entrance of an analyzed plan. We can solve it by using `resolveOperators` in `SubstituteUnresolvedOrdinals`. ## How was this patch tested? Added unit test case Author: liuxian <liu.xian3@zte.com.cn> Closes #18779 from 10110346/groupby.
-
Shixiong Zhu authored
## What changes were proposed in this pull request? This PR replaces #18623 to do some clean up. Closes #18623 ## How was this patch tested? Jenkins Author: Shixiong Zhu <shixiong@databricks.com> Author: Andrey Taptunov <taptunov@amazon.com> Closes #18848 from zsxwing/review-pr18623.
-
- Aug 04, 2017
-
-
Reynold Xin authored
## What changes were proposed in this pull request? OneRowRelation is the only plan that is a case object, which causes some issues with makeCopy using a 0-arg constructor. This patch changes it from a case object to a case class. This blocks SPARK-21619. ## How was this patch tested? Should be covered by existing test cases. Author: Reynold Xin <rxin@databricks.com> Closes #18839 from rxin/SPARK-21634.
-
Yuming Wang authored
## What changes were proposed in this pull request? Hive `pmod(3.13, 0)`: ```:sql hive> select pmod(3.13, 0); OK NULL Time taken: 2.514 seconds, Fetched: 1 row(s) hive> ``` Spark `mod(3.13, 0)`: ```:sql spark-sql> select mod(3.13, 0); NULL spark-sql> ``` But the Spark `pmod(3.13, 0)`: ```:sql spark-sql> select pmod(3.13, 0); 17/06/25 09:35:58 ERROR SparkSQLDriver: Failed in [select pmod(3.13, 0)] java.lang.NullPointerException at org.apache.spark.sql.catalyst.expressions.Pmod.pmod(arithmetic.scala:504) at org.apache.spark.sql.catalyst.expressions.Pmod.nullSafeEval(arithmetic.scala:432) at org.apache.spark.sql.catalyst.expressions.BinaryExpression.eval(Expression.scala:419) at org.apache.spark.sql.catalyst.expressions.UnaryExpression.eval(Expression.scala:323) ... ``` This PR make `pmod(number, 0)` to null. ## How was this patch tested? unit tests Author: Yuming Wang <wgyumg@gmail.com> Closes #18413 from wangyum/SPARK-21205.
-





























