- Sep 15, 2017
-
-
Yuming Wang authored
## What changes were proposed in this pull request? https://github.com/apache/spark/pull/18266 add a new feature to support read JDBC table use custom schema, but we must specify all the fields. For simplicity, this PR support specify partial fields. ## How was this patch tested? unit tests Author: Yuming Wang <wgyumg@gmail.com> Closes #19231 from wangyum/SPARK-22002.
-
- Sep 13, 2017
-
-
Yuming Wang authored
## What changes were proposed in this pull request? Auto generated Oracle schema some times not we expect: - `number(1)` auto mapped to BooleanType, some times it's not we expect, per [SPARK-20921](https://issues.apache.org/jira/browse/SPARK-20921). - `number` auto mapped to Decimal(38,10), It can't read big data, per [SPARK-20427](https://issues.apache.org/jira/browse/SPARK-20427). This PR fix this issue by custom schema as follows: ```scala val props = new Properties() props.put("customSchema", "ID decimal(38, 0), N1 int, N2 boolean") val dfRead = spark.read.schema(schema).jdbc(jdbcUrl, "tableWithCustomSchema", props) dfRead.show() ``` or ```sql CREATE TEMPORARY VIEW tableWithCustomSchema USING org.apache.spark.sql.jdbc OPTIONS (url '$jdbcUrl', dbTable 'tableWithCustomSchema', customSchema'ID decimal(38, 0), N1 int, N2 boolean') ``` ## How was this patch tested? unit tests Author: Yuming Wang <wgyumg@gmail.com> Closes #18266 from wangyum/SPARK-20427.
-
Sean Owen authored
## What changes were proposed in this pull request? Put Kafka 0.8 support behind a kafka-0-8 profile. ## How was this patch tested? Existing tests, but, until PR builder and Jenkins configs are updated the effect here is to not build or test Kafka 0.8 support at all. Author: Sean Owen <sowen@cloudera.com> Closes #19134 from srowen/SPARK-21893.
-
- Sep 12, 2017
-
-
Ajay Saini authored
# What changes were proposed in this pull request? Added tunable parallelism to the pyspark implementation of one vs. rest classification. Added a parallelism parameter to the Scala implementation of one vs. rest along with functionality for using the parameter to tune the level of parallelism. I take this PR #18281 over because the original author is busy but we need merge this PR soon. After this been merged, we can close #18281 . ## How was this patch tested? Test suite added. Author: Ajay Saini <ajays725@gmail.com> Author: WeichenXu <weichen.xu@databricks.com> Closes #19110 from WeichenXu123/spark-21027.
-
Kousuke Saruta authored
## What changes were proposed in this pull request? Recently, I found two unreachable links in the document and fixed them. Because of small changes related to the document, I don't file this issue in JIRA but please suggest I should do it if you think it's needed. ## How was this patch tested? Tested manually. Author: Kousuke Saruta <sarutak@oss.nttdata.co.jp> Closes #19195 from sarutak/fix-unreachable-link.
-
FavioVazquez authored
## What changes were proposed in this pull request? Fixed wrong documentation for Mean Absolute Error. Even though the code is correct for the MAE: ```scala Since("1.2.0") def meanAbsoluteError: Double = { summary.normL1(1) / summary.count } ``` In the documentation the division by N is missing. ## How was this patch tested? All of spark tests were run. Please review http://spark.apache.org/contributing.html before opening a pull request. Author: FavioVazquez <favio.vazquezp@gmail.com> Author: faviovazquez <favio.vazquezp@gmail.com> Author: Favio André Vázquez <favio.vazquezp@gmail.com> Closes #19190 from FavioVazquez/mae-fix.
-
- Sep 10, 2017
-
-
Jen-Ming Chung authored
## What changes were proposed in this pull request? ``` echo '{"field": 1} {"field": 2} {"field": "3"}' >/tmp/sample.json ``` ```scala import org.apache.spark.sql.types._ val schema = new StructType() .add("field", ByteType) .add("_corrupt_record", StringType) val file = "/tmp/sample.json" val dfFromFile = spark.read.schema(schema).json(file) scala> dfFromFile.show(false) +-----+---------------+ |field|_corrupt_record| +-----+---------------+ |1 |null | |2 |null | |null |{"field": "3"} | +-----+---------------+ scala> dfFromFile.filter($"_corrupt_record".isNotNull).count() res1: Long = 0 scala> dfFromFile.filter($"_corrupt_record".isNull).count() res2: Long = 3 ``` When the `requiredSchema` only contains `_corrupt_record`, the derived `actualSchema` is empty and the `_corrupt_record` are all null for all rows. This PR captures above situation and raise an exception with a reasonable workaround messag so that users can know what happened and how to fix the query. ## How was this patch tested? Added test case. Author: Jen-Ming Chung <jenmingisme@gmail.com> Closes #18865 from jmchung/SPARK-21610.
-
- Sep 07, 2017
-
-
Dongjoon Hyun authored
## What changes were proposed in this pull request? Since [SPARK-15639](https://github.com/apache/spark/pull/13701), `spark.sql.parquet.cacheMetadata` and `PARQUET_CACHE_METADATA` is not used. This PR removes from SQLConf and docs. ## How was this patch tested? Pass the existing Jenkins. Author: Dongjoon Hyun <dongjoon@apache.org> Closes #19129 from dongjoon-hyun/SPARK-13656.
-
- Sep 06, 2017
-
-
Bryan Cutler authored
## What changes were proposed in this pull request? Modified `CrossValidator` and `TrainValidationSplit` to be able to evaluate models in parallel for a given parameter grid. The level of parallelism is controlled by a parameter `numParallelEval` used to schedule a number of models to be trained/evaluated so that the jobs can be run concurrently. This is a naive approach that does not check the cluster for needed resources, so care must be taken by the user to tune the parameter appropriately. The default value is `1` which will train/evaluate in serial. ## How was this patch tested? Added unit tests for CrossValidator and TrainValidationSplit to verify that model selection is the same when run in serial vs parallel. Manual testing to verify tasks run in parallel when param is > 1. Added parameter usage to relevant examples. Author: Bryan Cutler <cutlerb@gmail.com> Closes #16774 from BryanCutler/parallel-model-eval-SPARK-19357.
-
Riccardo Corbella authored
## What changes were proposed in this pull request? Update the line "For example, the data (12:09, cat) is out of order and late, and it falls in windows 12:05 - 12:15 and 12:10 - 12:20." as follow "For example, the data (12:09, cat) is out of order and late, and it falls in windows 12:00 - 12:10 and 12:05 - 12:15." under the programming structured streaming programming guide. Author: Riccardo Corbella <r.corbella@reply.it> Closes #19137 from riccardocorbella/bugfix.
-
- Sep 05, 2017
-
-
Dongjoon Hyun authored
## What changes were proposed in this pull request? All built-in data sources support `Partition Discovery`. We had better update the document to give the users more benefit clearly. **AFTER** <img width="906" alt="1" src="https://user-images.githubusercontent.com/9700541/30083628-14278908-9244-11e7-98dc-9ad45fe233a9.png"> ## How was this patch tested? ``` SKIP_API=1 jekyll serve --watch ``` Author: Dongjoon Hyun <dongjoon@apache.org> Closes #19139 from dongjoon-hyun/partitiondiscovery.
-
Burak Yavuz authored
Forgot to update docs with behavior change. Author: Burak Yavuz <brkyvz@gmail.com> Closes #19138 from brkyvz/trigger-doc-fix.
-
- Aug 31, 2017
-
-
ArtRand authored
Mesos has secrets primitives for environment and file-based secrets, this PR adds that functionality to the Spark dispatcher and the appropriate configuration flags. Unit tested and manually tested against a DC/OS cluster with Mesos 1.4. Author: ArtRand <arand@soe.ucsc.edu> Closes #18837 from ArtRand/spark-20812-dispatcher-secrets-and-labels.
-
- Aug 30, 2017
-
-
Xiaofeng Lin authored
This patch adds statsd sink to the current metrics system in spark core. Author: Xiaofeng Lin <xlin@twilio.com> Closes #9518 from xflin/statsd. Change-Id: Ib8720e86223d4a650df53f51ceb963cd95b49a44
-
Bryan Cutler authored
## What changes were proposed in this pull request? This PR adds ML examples for the FeatureHasher transform in Scala, Java, Python. ## How was this patch tested? Manually ran examples and verified that output is consistent for different APIs Author: Bryan Cutler <cutlerb@gmail.com> Closes #19024 from BryanCutler/ml-examples-FeatureHasher-SPARK-21810.
-
- Aug 28, 2017
-
-
erenavsarogullari authored
## What changes were proposed in this pull request? Fair Scheduler can be built via one of the following options: - By setting a `spark.scheduler.allocation.file` property, - By setting `fairscheduler.xml` into classpath. These options are checked **in order** and fair-scheduler is built via first found option. If invalid path is found, `FileNotFoundException` will be expected. This PR aims unit test coverage of these use cases and a minor documentation change has been added for second option(`fairscheduler.xml` into classpath) to inform the users. Also, this PR was related with #16813 and has been created separately to keep patch content as isolated and to help the reviewers. ## How was this patch tested? Added new Unit Tests. Author: erenavsarogullari <erenavsarogullari@gmail.com> Closes #16992 from erenavsarogullari/SPARK-19662.
-
pgandhi authored
[SPARK-21798] No config to replace deprecated SPARK_CLASSPATH config for launching daemons like History Server History Server Launch uses SparkClassCommandBuilder for launching the server. It is observed that SPARK_CLASSPATH has been removed and deprecated. For spark-submit this takes a different route and spark.driver.extraClasspath takes care of specifying additional jars in the classpath that were previously specified in the SPARK_CLASSPATH. Right now the only way specify the additional jars for launching daemons such as history server is using SPARK_DIST_CLASSPATH (https://spark.apache.org/docs/latest/hadoop-provided.html) but this I presume is a distribution classpath. It would be nice to have a similar config like spark.driver.extraClasspath for launching daemons similar to history server. Added new environment variable SPARK_DAEMON_CLASSPATH to set classpath for launching daemons. Tested and verified for History Server and Standalone Mode. ## How was this patch tested? Initially, history server start script would fail for the reason being that it could not find the required jars for launching the server in the java classpath. Same was true for running Master and Worker in standalone mode. By adding the environment variable SPARK_DAEMON_CLASSPATH to the java classpath, both the daemons(History Server, Standalone daemons) are starting up and running. Author: pgandhi <pgandhi@yahoo-inc.com> Author: pgandhi999 <parthkgandhi9@gmail.com> Closes #19047 from pgandhi999/master.
-
- Aug 25, 2017
-
-
hyukjinkwon authored
## What changes were proposed in this pull request? This PR proposes both: - Add information about Javadoc, SQL docs and few more information in `docs/README.md` and a comment in `docs/_plugins/copy_api_dirs.rb` related with Javadoc. - Adds some commands so that the script always runs the SQL docs build under `./sql` directory (for directly running `./sql/create-docs.sh` in the root directory). ## How was this patch tested? Manual tests with `jekyll build` and `./sql/create-docs.sh` in the root directory. Author: hyukjinkwon <gurwls223@gmail.com> Closes #19019 from HyukjinKwon/minor-doc-build.
-
- Aug 24, 2017
-
-
Susan X. Huynh authored
JIRA ticket: https://issues.apache.org/jira/browse/SPARK-21694 ## What changes were proposed in this pull request? Spark already supports launching containers attached to a given CNI network by specifying it via the config `spark.mesos.network.name`. This PR adds support to pass in network labels to CNI plugins via a new config option `spark.mesos.network.labels`. These network labels are key-value pairs that are set in the `NetworkInfo` of both the driver and executor tasks. More details in the related Mesos documentation: http://mesos.apache.org/documentation/latest/cni/#mesos-meta-data-to-cni-plugins ## How was this patch tested? Unit tests, for both driver and executor tasks. Manual integration test to submit a job with the `spark.mesos.network.labels` option, hit the mesos/state.json endpoint, and check that the labels are set in the driver and executor tasks. ArtRand skonto Author: Susan X. Huynh <xhuynh@mesosphere.com> Closes #18910 from susanxhuynh/sh-mesos-cni-labels.
-
- Aug 23, 2017
-
-
Sanket Chintapalli authored
Right now the spark shuffle service has a cache for index files. It is based on a # of files cached (spark.shuffle.service.index.cache.entries). This can cause issues if people have a lot of reducers because the size of each entry can fluctuate based on the # of reducers. We saw an issues with a job that had 170000 reducers and it caused NM with spark shuffle service to use 700-800MB or memory in NM by itself. We should change this cache to be memory based and only allow a certain memory size used. When I say memory based I mean the cache should have a limit of say 100MB. https://issues.apache.org/jira/browse/SPARK-21501 Manual Testing with 170000 reducers has been performed with cache loaded up to max 100MB default limit, with each shuffle index file of size 1.3MB. Eviction takes place as soon as the total cache size reaches the 100MB limit and the objects will be ready for garbage collection there by avoiding NM to crash. No notable difference in runtime has been observed. Author: Sanket Chintapalli <schintap@yahoo-inc.com> Closes #18940 from redsanket/SPARK-21501.
-
- Aug 20, 2017
-
-
hyukjinkwon authored
## What changes were proposed in this pull request? This PR proposes to install `mkdocs` by `pip install` if missing in the path. Mainly to fix Jenkins's documentation build failure in `spark-master-docs`. See https://amplab.cs.berkeley.edu/jenkins/job/spark-master-docs/3580/console. It also adds `mkdocs` as requirements in `docs/README.md`. ## How was this patch tested? I manually ran `jekyll build` under `docs` directory after manually removing `mkdocs` via `pip uninstall mkdocs`. Also, tested this in the same way but on CentOS Linux release 7.3.1611 (Core) where I built Spark few times but never built documentation before and `mkdocs` is not installed. ``` ... Moving back into docs dir. Moving to SQL directory and building docs. Missing mkdocs in your path, trying to install mkdocs for SQL documentation generation. Collecting mkdocs Downloading mkdocs-0.16.3-py2.py3-none-any.whl (1.2MB) 100% |████████████████████████████████| 1.2MB 574kB/s Requirement already satisfied: PyYAML>=3.10 in /usr/lib64/python2.7/site-packages (from mkdocs) Collecting livereload>=2.5.1 (from mkdocs) Downloading livereload-2.5.1-py2-none-any.whl Collecting tornado>=4.1 (from mkdocs) Downloading tornado-4.5.1.tar.gz (483kB) 100% |████████████████████████████████| 491kB 1.4MB/s Collecting Markdown>=2.3.1 (from mkdocs) Downloading Markdown-2.6.9.tar.gz (271kB) 100% |████████████████████████████████| 276kB 2.4MB/s Collecting click>=3.3 (from mkdocs) Downloading click-6.7-py2.py3-none-any.whl (71kB) 100% |████████████████████████████████| 71kB 2.8MB/s Requirement already satisfied: Jinja2>=2.7.1 in /usr/lib/python2.7/site-packages (from mkdocs) Requirement already satisfied: six in /usr/lib/python2.7/site-packages (from livereload>=2.5.1->mkdocs) Requirement already satisfied: backports.ssl_match_hostname in /usr/lib/python2.7/site-packages (from tornado>=4.1->mkdocs) Collecting singledispatch (from tornado>=4.1->mkdocs) Downloading singledispatch-3.4.0.3-py2.py3-none-any.whl Collecting certifi (from tornado>=4.1->mkdocs) Downloading certifi-2017.7.27.1-py2.py3-none-any.whl (349kB) 100% |████████████████████████████████| 358kB 2.1MB/s Collecting backports_abc>=0.4 (from tornado>=4.1->mkdocs) Downloading backports_abc-0.5-py2.py3-none-any.whl Requirement already satisfied: MarkupSafe>=0.23 in /usr/lib/python2.7/site-packages (from Jinja2>=2.7.1->mkdocs) Building wheels for collected packages: tornado, Markdown Running setup.py bdist_wheel for tornado ... done Stored in directory: /root/.cache/pip/wheels/84/83/cd/6a04602633457269d161344755e6766d24307189b7a67ff4b7 Running setup.py bdist_wheel for Markdown ... done Stored in directory: /root/.cache/pip/wheels/bf/46/10/c93e17ae86ae3b3a919c7b39dad3b5ccf09aeb066419e5c1e5 Successfully built tornado Markdown Installing collected packages: singledispatch, certifi, backports-abc, tornado, livereload, Markdown, click, mkdocs Successfully installed Markdown-2.6.9 backports-abc-0.5 certifi-2017.7.27.1 click-6.7 livereload-2.5.1 mkdocs-0.16.3 singledispatch-3.4.0.3 tornado-4.5.1 Generating markdown files for SQL documentation. Generating HTML files for SQL documentation. INFO - Cleaning site directory INFO - Building documentation to directory: .../spark/sql/site Moving back into docs dir. Making directory api/sql cp -r ../sql/site/. api/sql Source: .../spark/docs Destination: .../spark/docs/_site Generating... done. Auto-regeneration: disabled. Use --watch to enable. ``` Author: hyukjinkwon <gurwls223@gmail.com> Closes #18984 from HyukjinKwon/sql-doc-mkdocs.
-
- Aug 11, 2017
-
-
LucaCanali authored
Add an option to the JDBC data source to initialize the environment of the remote database session ## What changes were proposed in this pull request? This proposes an option to the JDBC datasource, tentatively called " sessionInitStatement" to implement the functionality of session initialization present for example in the Sqoop connector for Oracle (see https://sqoop.apache.org/docs/1.4.6/SqoopUserGuide.html#_oraoop_oracle_session_initialization_statements ) . After each database session is opened to the remote DB, and before starting to read data, this option executes a custom SQL statement (or a PL/SQL block in the case of Oracle). See also https://issues.apache.org/jira/browse/SPARK-21519 ## How was this patch tested? Manually tested using Spark SQL data source and Oracle JDBC Author: LucaCanali <luca.canali@cern.ch> Closes #18724 from LucaCanali/JDBC_datasource_sessionInitStatement.
-
- Aug 08, 2017
-
-
Marcos P. Sanchez authored
## What changes were proposed in this pull request? This commit adds a new argument for IllegalArgumentException message. This recent commit added the argument: [https://github.com/apache/spark/commit/dcac1d57f0fd05605edf596c303546d83062a352](https://github.com/apache/spark/commit/dcac1d57f0fd05605edf596c303546d83062a352) ## How was this patch tested? Unit test have been passed Please review http://spark.apache.org/contributing.html before opening a pull request. Author: Marcos P. Sanchez <mpenate@stratio.com> Closes #18862 from mpenate/feature/exception-errorifexists.
-
- Aug 07, 2017
-
-
Stavros Kontopoulos authored
## What changes were proposed in this pull request? Adds a sandbox link per driver in the dispatcher ui with minimal changes after a bug was fixed here: https://issues.apache.org/jira/browse/MESOS-4992 The sandbox uri has the following format: http://<proxy_uri>/#/slaves/\<agent-id\>/ frameworks/ \<scheduler-id\>/executors/\<driver-id\>/browse For dc/os the proxy uri is <dc/os uri>/mesos. For the dc/os deployment scenario and to make things easier I introduced a new config property named `spark.mesos.proxy.baseURL` which should be passed to the dispatcher when launched using --conf. If no such configuration is detected then no sandbox uri is depicted, and there is an empty column with a header (this can be changed so nothing is shown). Within dc/os the base url must be a property for the dispatcher that we should add in the future here: https://github.com/mesosphere/universe/blob/9e7c909c3b8680eeb0494f2a58d5746e3bab18c1/repo/packages/S/spark/26/config.json It is not easy to detect in different environments what is that uri so user should pass it. ## How was this patch tested? Tested with the mesos test suite here: https://github.com/typesafehub/mesos-spark-integration-tests. Attached image shows the ui modification where the sandbox header is added. 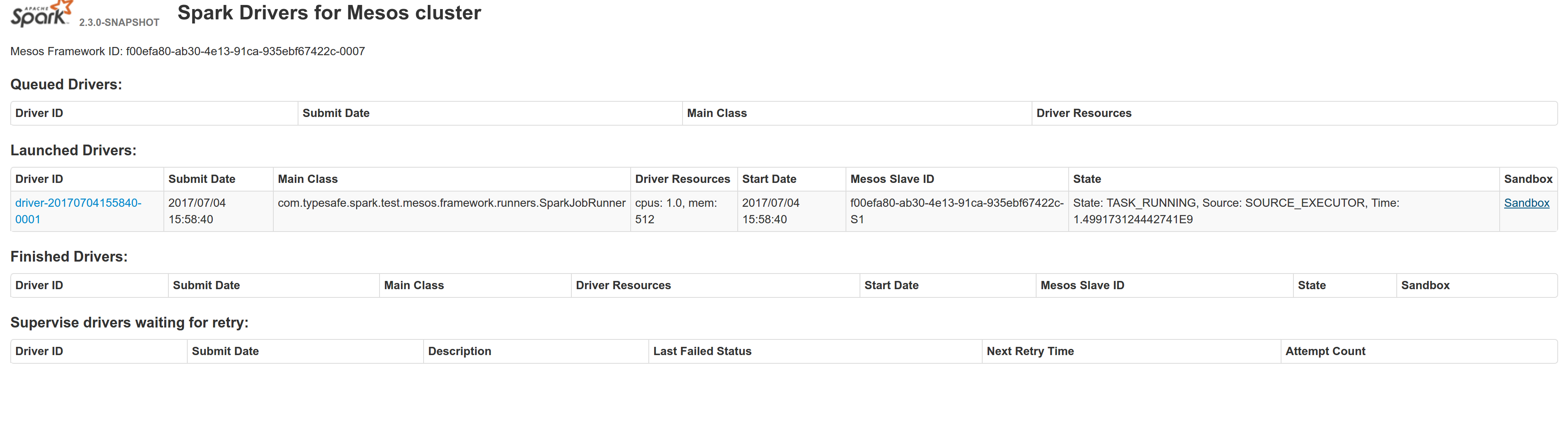 Tested the uri redirection the way it was suggested here: https://issues.apache.org/jira/browse/MESOS-4992 Built mesos 1.4 from the master branch and started the mesos dispatcher with the command: `./sbin/start-mesos-dispatcher.sh --conf spark.mesos.proxy.baseURL=http://localhost:5050 -m mesos://127.0.0.1:5050` Run a spark example: `./bin/spark-submit --class org.apache.spark.examples.SparkPi --master mesos://10.10.1.79:7078 --deploy-mode cluster --executor-memory 2G --total-executor-cores 2 http://<path>/spark-examples_2.11-2.1.1.jar 10` Sandbox uri is shown at the bottom of the page: 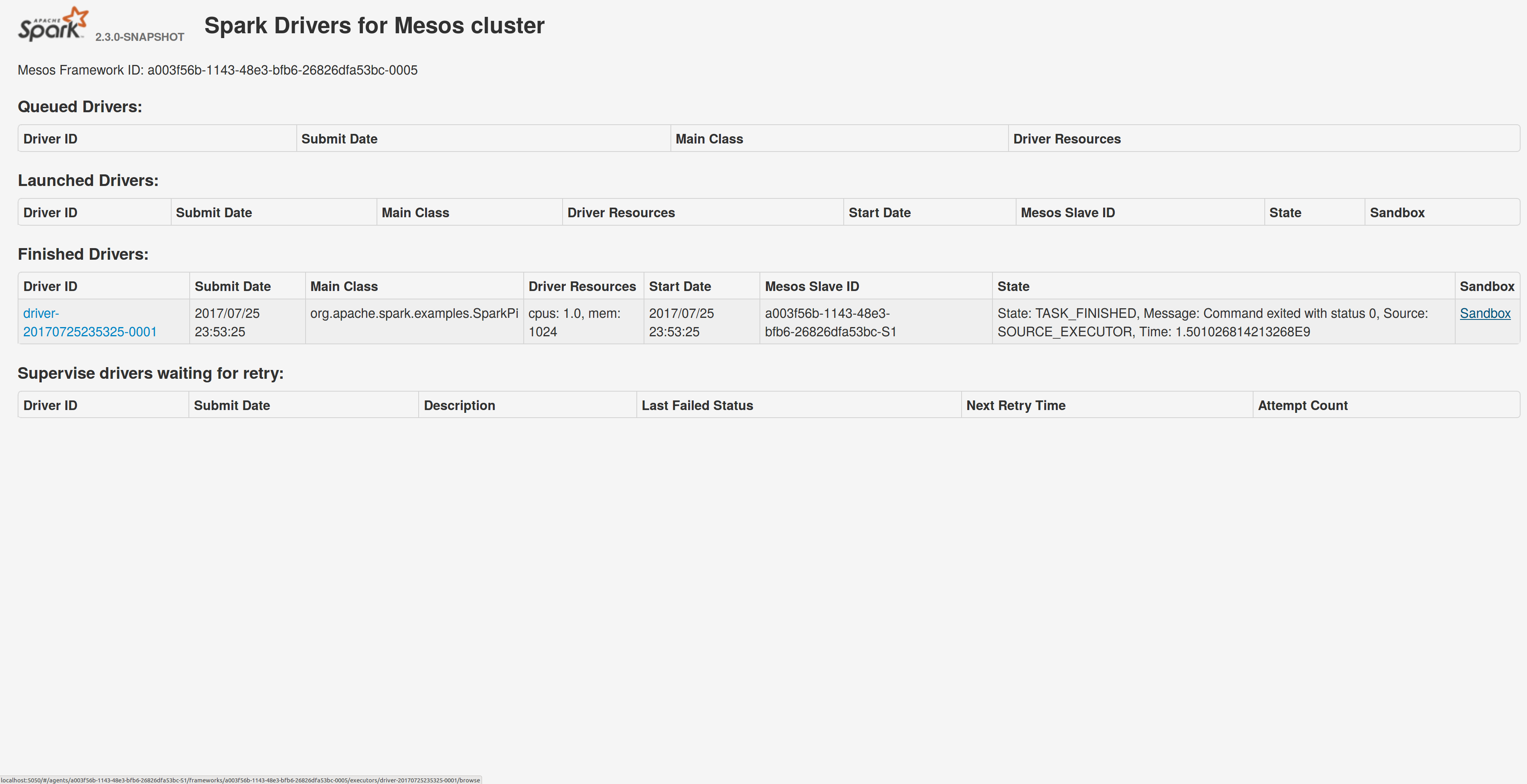 Redirection works as expected: 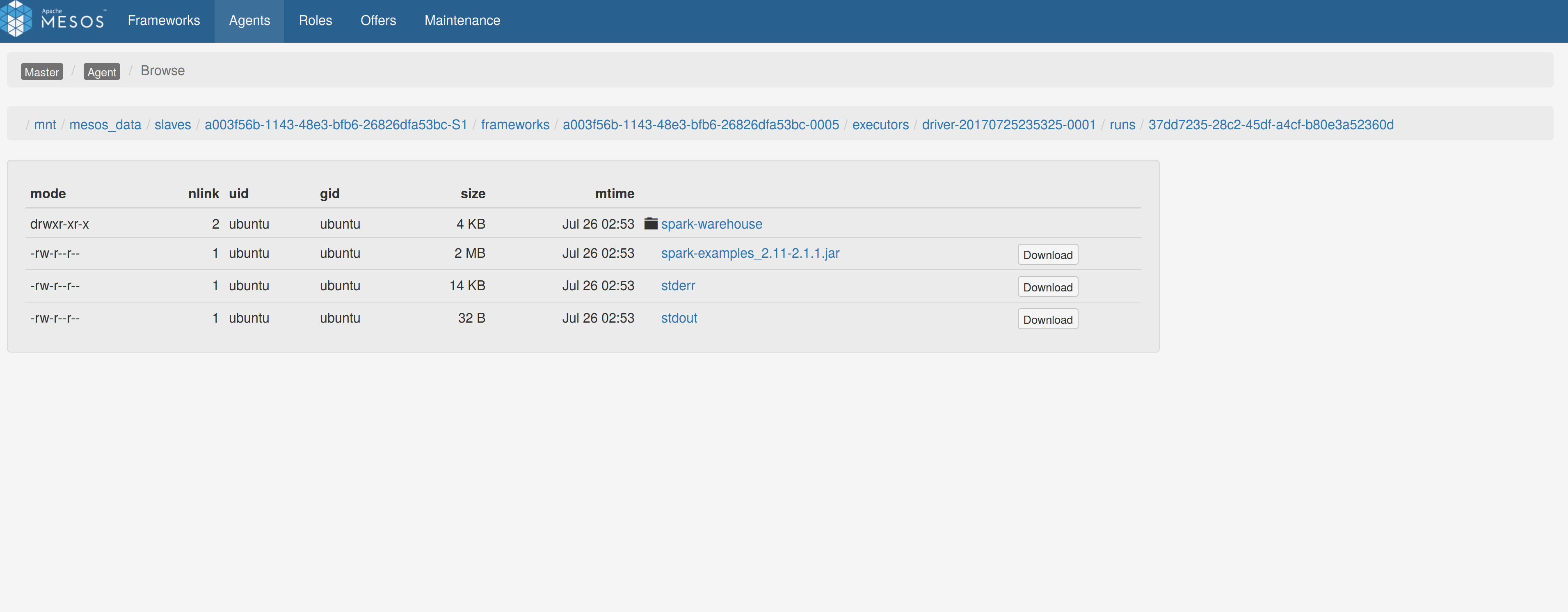 Author: Stavros Kontopoulos <st.kontopoulos@gmail.com> Closes #18528 from skonto/adds_the_sandbox_uri.
-
- Aug 05, 2017
-
-
hzyaoqin authored
## What changes were proposed in this pull request? When we use `bin/spark-sql` command configuring `--conf spark.hadoop.foo=bar`, the `SparkSQLCliDriver` initializes an instance of hiveconf, it does not add `foo->bar` to it. this pr gets `spark.hadoop.*` properties from sysProps to this hiveconf ## How was this patch tested? UT Author: hzyaoqin <hzyaoqin@corp.netease.com> Author: Kent Yao <yaooqinn@hotmail.com> Closes #18668 from yaooqinn/SPARK-21451.
-
- Aug 03, 2017
-
-
Christiam Camacho authored
## What changes were proposed in this pull request? Add missing import and missing parentheses to invoke `SparkSession::text()`. ## How was this patch tested? Built and the code for this application, ran jekyll locally per docs/README.md. Author: Christiam Camacho <camacho@ncbi.nlm.nih.gov> Closes #18795 from christiam/master.
-
Ayush Singh authored
[SPARK-21615][ML][MLLIB][DOCS] Fix broken redirect in collaborative filtering docs to databricks training repo ## What changes were proposed in this pull request? * Current [MLlib Collaborative Filtering tutorial](https://spark.apache.org/docs/latest/mllib-collaborative-filtering.html) points to broken links to old databricks website. * Databricks moved all their content to [git repo](https://github.com/databricks/spark-training) * Two links needs to be fixed, * [training exercises](https://databricks-training.s3.amazonaws.com/index.html) * [personalized movie recommendation with spark.mllib](https://databricks-training.s3.amazonaws.com/movie-recommendation-with-mllib.html) ## How was this patch tested? Generated docs locally Author: Ayush Singh <singhay@ccs.neu.edu> Closes #18821 from singhay/SPARK-21615.
-
- Aug 01, 2017
-
-
Sean Owen authored
## What changes were proposed in this pull request? Fix 2 rendering errors on configuration doc page, due to SPARK-21243 and SPARK-15355. ## How was this patch tested? Manually built and viewed docs with jekyll Author: Sean Owen <sowen@cloudera.com> Closes #18793 from srowen/SPARK-21593.
-
Takeshi Yamamuro authored
## What changes were proposed in this pull request? This pr added documents about unsupported functions in Hive UDF/UDTF/UDAF. This pr relates to #18768 and #18527. ## How was this patch tested? N/A Author: Takeshi Yamamuro <yamamuro@apache.org> Closes #18792 from maropu/HOTFIX-20170731.
-
- Jul 30, 2017
-
-
Cheng Wang authored
In programming guide, `numTasks` is used in several places as arguments of Transformations. However, in code, `numPartitions` is used. In this fix, I replace `numTasks` with `numPartitions` in programming guide for consistency. Author: Cheng Wang <chengwang0511@gmail.com> Closes #18774 from polarke/replace-numtasks-with-numpartitions-in-doc.
-
- Jul 29, 2017
-
-
Remis Haroon authored
## What changes were proposed in this pull request? JIRA ticket : [SPARK-21508](https://issues.apache.org/jira/projects/SPARK/issues/SPARK-21508) correcting a mistake in example code provided in Spark Streaming Custom Receivers Documentation The example code provided in the documentation on 'Spark Streaming Custom Receivers' has an error. doc link : https://spark.apache.org/docs/latest/streaming-custom-receivers.html ``` // Assuming ssc is the StreamingContext val customReceiverStream = ssc.receiverStream(new CustomReceiver(host, port)) val words = lines.flatMap(_.split(" ")) ... ``` instead of `lines.flatMap(_.split(" "))` it should be `customReceiverStream.flatMap(_.split(" "))` ## How was this patch tested? this documentation change is tested manually by jekyll build , running below commands ``` jekyll build jekyll serve --watch ``` screen-shots provided below   Author: Remis Haroon <Remis.Haroon@insdc01.pwc.com> Closes #18770 from remisharoon/master.
-
- Jul 26, 2017
-
-
jinxing authored
## What changes were proposed in this pull request? Update the description of `spark.shuffle.maxChunksBeingTransferred` to include that the new coming connections will be closed when the max is hit and client should have retry mechanism. Author: jinxing <jinxing6042@126.com> Closes #18735 from jinxing64/SPARK-21530.
-
hyukjinkwon authored
## What changes were proposed in this pull request? This generates a documentation for Spark SQL built-in functions. One drawback is, this requires a proper build to generate built-in function list. Once it is built, it only takes few seconds by `sql/create-docs.sh`. Please see https://spark-test.github.io/sparksqldoc/ that I hosted to show the output documentation. There are few more works to be done in order to make the documentation pretty, for example, separating `Arguments:` and `Examples:` but I guess this should be done within `ExpressionDescription` and `ExpressionInfo` rather than manually parsing it. I will fix these in a follow up. This requires `pip install mkdocs` to generate HTMLs from markdown files. ## How was this patch tested? Manually tested: ``` cd docs jekyll build ``` , ``` cd docs jekyll serve ``` and ``` cd sql create-docs.sh ``` Author: hyukjinkwon <gurwls223@gmail.com> Closes #18702 from HyukjinKwon/SPARK-21485.
-
- Jul 25, 2017
-
-
jinxing authored
## What changes were proposed in this pull request? A shuffle service can serves blocks from multiple apps/tasks. Thus the shuffle service can suffers high memory usage when lots of shuffle-reads happen at the same time. In my cluster, OOM always happens on shuffle service. Analyzing heap dump, memory cost by Netty(ChannelOutboundBufferEntry) can be up to 2~3G. It might make sense to reject "open blocks" request when memory usage is high on shuffle service. https://github.com/apache/spark/commit/93dd0c518d040155b04e5ab258c5835aec7776fc and https://github.com/apache/spark/commit/85c6ce61930490e2247fb4b0e22dfebbb8b6a1ee tried to alleviate the memory pressure on shuffle service but cannot solve the root cause. This pr proposes to control currency of shuffle read. ## How was this patch tested? Added unit test. Author: jinxing <jinxing6042@126.com> Closes #18388 from jinxing64/SPARK-21175.
-
Trueman authored
I find a bug about 'quick start',and created a new issues,Sean Owen let me to make a pull request, and I do ## What changes were proposed in this pull request? (Please fill in changes proposed in this fix) ## How was this patch tested? (Please explain how this patch was tested. E.g. unit tests, integration tests, manual tests) (If this patch involves UI changes, please attach a screenshot; otherwise, remove this) Please review http://spark.apache.org/contributing.html before opening a pull request. Author: Trueman <lizhaoch@users.noreply.github.com> Author: lizhaoch <lizhaoc@163.com> Closes #18722 from lizhaoch/master.
-
Yash Sharma authored
[SPARK-20855][Docs][DStream] Update the Spark kinesis docs to use the KinesisInputDStream builder instead of deprecated KinesisUtils ## What changes were proposed in this pull request? The examples and docs for Spark-Kinesis integrations use the deprecated KinesisUtils. We should update the docs to use the KinesisInputDStream builder to create DStreams. ## How was this patch tested? The patch primarily updates the documents. The patch will also need to make changes to the Spark-Kinesis examples. The examples need to be tested. Author: Yash Sharma <ysharma@atlassian.com> Closes #18071 from yssharma/ysharma/kinesis_docs.
-
- Jul 21, 2017
-
-
Holden Karau authored
## What changes were proposed in this pull request? Update the Quickstart and RDD programming guides to mention pip. ## How was this patch tested? Built docs locally. Author: Holden Karau <holden@us.ibm.com> Closes #18698 from holdenk/SPARK-21434-add-pyspark-pip-documentation.
-
Liang-Chi Hsieh authored
## What changes were proposed in this pull request? Minor change to kafka integration document for structured streaming. ## How was this patch tested? N/A, doc change only. Author: Liang-Chi Hsieh <viirya@gmail.com> Closes #18550 from viirya/minor-ss-kafka-doc.
-
- Jul 20, 2017
-
-
hyukjinkwon authored
## What changes were proposed in this pull request? After SPARK-12661, I guess we officially dropped Python 2.6 support. It looks there are few places missing this notes. I grepped "Python 2.6" and "python 2.6" and the results were below: ``` ./core/src/main/scala/org/apache/spark/api/python/SerDeUtil.scala: // Unpickle array.array generated by Python 2.6 ./docs/index.md:Note that support for Java 7, Python 2.6 and old Hadoop versions before 2.6.5 were removed as of Spark 2.2.0. ./docs/rdd-programming-guide.md:Spark {{site.SPARK_VERSION}} works with Python 2.6+ or Python 3.4+. It can use the standard CPython interpreter, ./docs/rdd-programming-guide.md:Note that support for Python 2.6 is deprecated as of Spark 2.0.0, and may be removed in Spark 2.2.0. ./python/pyspark/context.py: warnings.warn("Support for Python 2.6 is deprecated as of Spark 2.0.0") ./python/pyspark/ml/tests.py: sys.stderr.write('Please install unittest2 to test with Python 2.6 or earlier') ./python/pyspark/mllib/tests.py: sys.stderr.write('Please install unittest2 to test with Python 2.6 or earlier') ./python/pyspark/serializers.py: # On Python 2.6, we can't write bytearrays to streams, so we need to convert them ./python/pyspark/sql/tests.py: sys.stderr.write('Please install unittest2 to test with Python 2.6 or earlier') ./python/pyspark/streaming/tests.py: sys.stderr.write('Please install unittest2 to test with Python 2.6 or earlier') ./python/pyspark/tests.py: sys.stderr.write('Please install unittest2 to test with Python 2.6 or earlier') ./python/pyspark/tests.py: # NOTE: dict is used instead of collections.Counter for Python 2.6 ./python/pyspark/tests.py: # NOTE: dict is used instead of collections.Counter for Python 2.6 ``` This PR only proposes to change visible changes as below: ``` ./docs/rdd-programming-guide.md:Spark {{site.SPARK_VERSION}} works with Python 2.6+ or Python 3.4+. It can use the standard CPython interpreter, ./docs/rdd-programming-guide.md:Note that support for Python 2.6 is deprecated as of Spark 2.0.0, and may be removed in Spark 2.2.0. ./python/pyspark/context.py: warnings.warn("Support for Python 2.6 is deprecated as of Spark 2.0.0") ``` This one is already correct: ``` ./docs/index.md:Note that support for Java 7, Python 2.6 and old Hadoop versions before 2.6.5 were removed as of Spark 2.2.0. ``` ## How was this patch tested? ```bash grep -r "Python 2.6" . grep -r "python 2.6" . ``` Author: hyukjinkwon <gurwls223@gmail.com> Closes #18682 from HyukjinKwon/minor-python.26.
-
- Jul 19, 2017
-
-
Susan X. Huynh authored
## What changes were proposed in this pull request? Current behavior: in Mesos cluster mode, the driver failover_timeout is set to zero. If the driver temporarily loses connectivity with the Mesos master, the framework will be torn down and all executors killed. Proposed change: make the failover_timeout configurable via a new option, spark.mesos.driver.failoverTimeout. The default value is still zero. Note: with non-zero failover_timeout, an explicit teardown is needed in some cases. This is captured in https://issues.apache.org/jira/browse/SPARK-21458 ## How was this patch tested? Added a unit test to make sure the config option is set while creating the scheduler driver. Ran an integration test with mesosphere/spark showing that with a non-zero failover_timeout the Spark job finishes after a driver is disconnected from the master. Author: Susan X. Huynh <xhuynh@mesosphere.com> Closes #18674 from susanxhuynh/sh-mesos-failover-timeout.
-






























