- Jul 28, 2017
-
-
pgandhi authored
[SPARK-21541][YARN] Spark Logs show incorrect job status for a job that does not create SparkContext If you run a spark job without creating the SparkSession or SparkContext, the spark job logs says it succeeded but yarn says it fails and retries 3 times. Also, since, Application Master unregisters with Resource Manager and exits successfully, it deletes the spark staging directory, so when yarn makes subsequent retries, it fails to find the staging directory and thus, the retries fail. Added a flag to check whether user has initialized SparkContext. If it is true, we let Application Master unregister with Resource Manager else, we do not let AM unregister with RM. ## How was this patch tested? Manually tested the fix. Before: <img width="1253" alt="screen shot-before" src="https://user-images.githubusercontent.com/22228190/28647214-69bf81e2-722b-11e7-9ed0-d416d2bf23be.png"> After: <img width="1319" alt="screen shot-after" src="https://user-images.githubusercontent.com/22228190/28647220-70f9eea2-722b-11e7-85c6-e56276b15614.png"> Please review http://spark.apache.org/contributing.html before opening a pull request. Author: pgandhi <pgandhi@yahoo-inc.com> Author: pgandhi999 <parthkgandhi9@gmail.com> Closes #18741 from pgandhi999/SPARK-21541.
-
- Jul 25, 2017
-
-
Marcelo Vanzin authored
There was some code based on the old SASL handler in the new auth client that was incorrectly using the SASL user as the user to authenticate against the external shuffle service. This caused the external service to not be able to find the correct secret to authenticate the connection, failing the connection. In the course of debugging, I found that some log messages from the YARN shuffle service were a little noisy, so I silenced some of them, and also added a couple of new ones that helped find this issue. On top of that, I found that a check in the code that records app secrets was wrong, causing more log spam and also using an O(n) operation instead of an O(1) call. Also added a new integration suite for the YARN shuffle service with auth on, and verified it failed before, and passes now. Author: Marcelo Vanzin <vanzin@cloudera.com> Closes #18706 from vanzin/SPARK-21494.
-
DjvuLee authored
When NodeManagers launching Executors, the `missing` value will exceed the real value when the launch is slow, this can lead to YARN allocates more resource. We add the `numExecutorsRunning` when calculate the `missing` to avoid this. Test by experiment. Author: DjvuLee <lihu@bytedance.com> Closes #18651 from djvulee/YarnAllocate.
-
- Jul 24, 2017
-
-
Stavros Kontopoulos authored
## What changes were proposed in this pull request? With supervise enabled for a driver, re-launching it was failing because the driver had the same framework Id. This patch creates a new driver framework id every time we re-launch a driver, but we keep the driver submission id the same since that is the same with the task id the driver was launched with on mesos and retry state and other info within Dispatcher's data structures uses that as a key. We append a "-retry-%4d" string as a suffix to the framework id passed by the dispatcher to the driver and the same value to the app_id created by each driver, except the first time where we dont need the retry suffix. The previous format for the frameworkId was 'DispactherFId-DriverSubmissionId'. We also detect the case where we have multiple spark contexts started from within the same driver and we do set proper names to their corresponding app-ids. The old practice was to unset the framework id passed from the dispatcher after the driver framework was started for the first time and let mesos decide the framework ID for subsequent spark contexts. The decided fId was passed as an appID. This patch affects heavily the history server. Btw we dont have the issues of the standalone case where driver id must be different since the dispatcher will re-launch a driver(mesos task) only if it gets an update that it is dead and this is verified by mesos implicitly. We also dont fix the fine grained mode which is deprecated and of no use. ## How was this patch tested? This task was manually tested on dc/os. Launched a driver, stoped its container and verified the expected behavior. Initial retry of the driver, driver in pending state:  Driver re-launched: 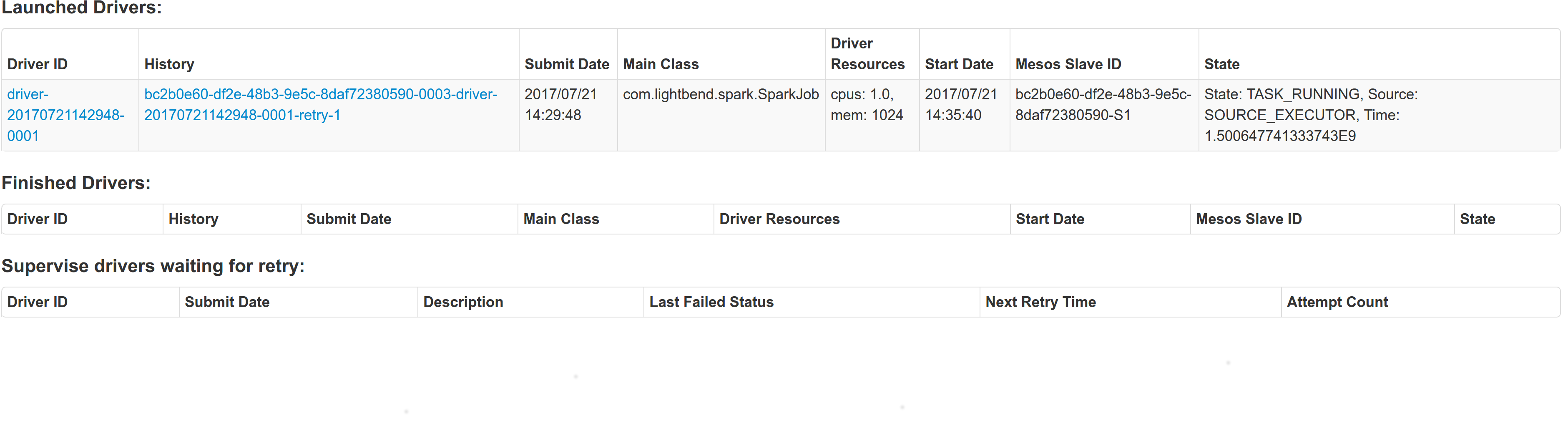 Another re-try:  The resulted entries in history server at the bottom: 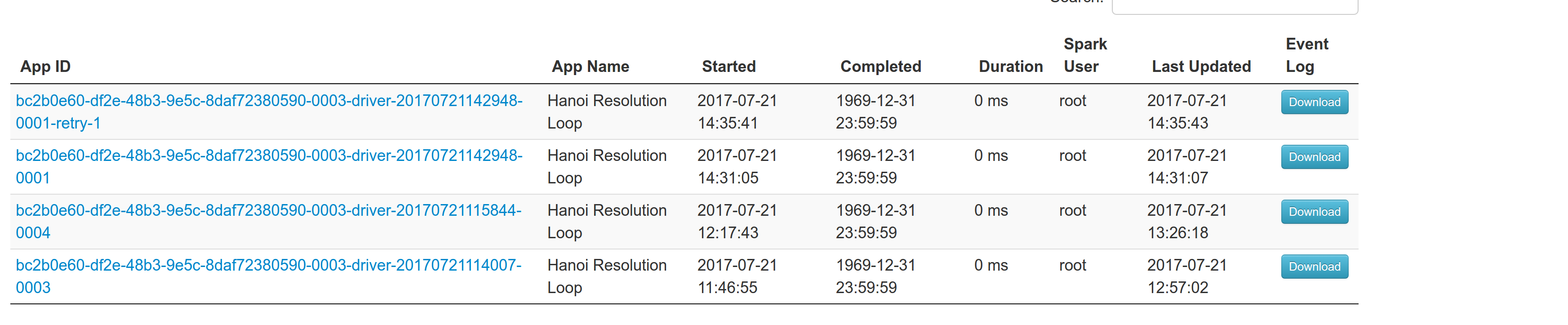 Regarding multiple spark contexts here is the end result regarding the spark history server, for the second spark context we add an increasing number as a suffix:  Author: Stavros Kontopoulos <st.kontopoulos@gmail.com> Closes #18705 from skonto/fix_supervise_flag.
-
- Jul 19, 2017
-
-
Susan X. Huynh authored
## What changes were proposed in this pull request? Current behavior: in Mesos cluster mode, the driver failover_timeout is set to zero. If the driver temporarily loses connectivity with the Mesos master, the framework will be torn down and all executors killed. Proposed change: make the failover_timeout configurable via a new option, spark.mesos.driver.failoverTimeout. The default value is still zero. Note: with non-zero failover_timeout, an explicit teardown is needed in some cases. This is captured in https://issues.apache.org/jira/browse/SPARK-21458 ## How was this patch tested? Added a unit test to make sure the config option is set while creating the scheduler driver. Ran an integration test with mesosphere/spark showing that with a non-zero failover_timeout the Spark job finishes after a driver is disconnected from the master. Author: Susan X. Huynh <xhuynh@mesosphere.com> Closes #18674 from susanxhuynh/sh-mesos-failover-timeout.
-
- Jul 18, 2017
-
-
Marcelo Vanzin authored
Instead of using the host's cpu count, use the number of cores allocated for the Spark process when sizing the RPC dispatch thread pool. This avoids creating large thread pools on large machines when the number of allocated cores is small. Tested by verifying number of threads with spark.executor.cores set to 1 and 4; same thing for YARN AM. Author: Marcelo Vanzin <vanzin@cloudera.com> Closes #18639 from vanzin/SPARK-21408.
-
jerryshao authored
## What changes were proposed in this pull request? In the current `YARNHadoopDelegationTokenManager`, `FileSystem` to which to get tokens are created out of KDC logged UGI, using these `FileSystem` to get new tokens will lead to exception. The main thing is that Spark code trying to get new tokens from the FS created with token auth-ed UGI, but Hadoop can only grant new tokens in kerberized UGI. To fix this issue, we should lazily create these FileSystem within KDC logged UGI. ## How was this patch tested? Manual verification in secure cluster. CC vanzin mgummelt please help to review, thanks! Author: jerryshao <sshao@hortonworks.com> Closes #18633 from jerryshao/SPARK-21411.
-
Sean Owen authored
## What changes were proposed in this pull request? Address scapegoat warnings for: - BigDecimal double constructor - Catching NPE - Finalizer without super - List.size is O(n) - Prefer Seq.empty - Prefer Set.empty - reverse.map instead of reverseMap - Type shadowing - Unnecessary if condition. - Use .log1p - Var could be val In some instances like Seq.empty, I avoided making the change even where valid in test code to keep the scope of the change smaller. Those issues are concerned with performance and it won't matter for tests. ## How was this patch tested? Existing tests Author: Sean Owen <sowen@cloudera.com> Closes #18635 from srowen/Scapegoat1.
-
- Jul 17, 2017
-
-
jerryshao authored
## What changes were proposed in this pull request? In this issue we have a long running Spark application with secure HBase, which requires `HBaseCredentialProvider` to get tokens periodically, we specify HBase related jars with `--packages`, but these dependencies are not added into AM classpath, so when `HBaseCredentialProvider` tries to initialize HBase connections to get tokens, it will be failed. Currently because jars specified with `--jars` or `--packages` are not added into AM classpath, the only way to extend AM classpath is to use "spark.driver.extraClassPath" which supposed to be used in yarn cluster mode. So in this fix, we proposed to use/reuse a classloader for `AMCredentialRenewer` to acquire new tokens. Also in this patch, we fixed AM cannot get tokens from HDFS issue, it is because FileSystem is gotten before kerberos logged, so using this FS to get tokens will throw exception. ## How was this patch tested? Manual verification. Author: jerryshao <sshao@hortonworks.com> Closes #18616 from jerryshao/SPARK-21377.
-
John Lee authored
## What changes were proposed in this pull request? The current code is very verbose on shutdown. The changes I propose is to change the log level when the driver is shutting down and the RPC connections are closed (RpcEnvStoppedException). ## How was this patch tested? Tested with word count(deploy-mode = cluster, master = yarn, num-executors = 4) with 300GB of data. Author: John Lee <jlee2@yahoo-inc.com> Closes #18547 from yoonlee95/SPARK-21321.
-
- Jul 14, 2017
-
-
Marcelo Vanzin authored
When localizing the gateway config files in a YARN application, avoid overwriting final configs by distributing the gateway files to a separate directory, and explicitly loading them into the Hadoop config, instead of placing those files before the cluster's files in the classpath. This is done by saving the gateway's config to a separate XML file distributed with the rest of the Spark app's config, and loading that file when creating a new config through `YarnSparkHadoopUtil`. Tested with existing unit tests, and by verifying the behavior in a YARN cluster (final values are not overridden, non-final values are). Author: Marcelo Vanzin <vanzin@cloudera.com> Closes #18370 from vanzin/SPARK-9825.
-
- Jul 13, 2017
-
-
jerryshao authored
[SPARK-21376][YARN] Fix yarn client token expire issue when cleaning the staging files in long running scenario ## What changes were proposed in this pull request? This issue happens in long running application with yarn cluster mode, because yarn#client doesn't sync token with AM, so it will always keep the initial token, this token may be expired in the long running scenario, so when yarn#client tries to clean up staging directory after application finished, it will use this expired token and meet token expire issue. ## How was this patch tested? Manual verification is secure cluster. Author: jerryshao <sshao@hortonworks.com> Closes #18617 from jerryshao/SPARK-21376.
-
- Jul 12, 2017
-
-
Devaraj K authored
## What changes were proposed in this pull request? Adding the default UncaughtExceptionHandler to the Worker. ## How was this patch tested? I verified it manually, when any of the worker thread gets uncaught exceptions then the default UncaughtExceptionHandler will handle those exceptions. Author: Devaraj K <devaraj@apache.org> Closes #18357 from devaraj-kavali/SPARK-21146.
-
- Jul 11, 2017
-
-
Marcelo Vanzin authored
Currently the code monitoring the launch of the client AM uses the value of spark.yarn.report.interval as the interval for polling the RM; if someone has that value to a really large interval, it would take that long to detect that the client AM has started, which is not expected. Instead, have a separate config for the interval to use when the client AM is starting. The other config is still used in cluster mode, and to detect the status of the client AM after it is already running. Tested by running client and cluster mode apps with a modified value of spark.yarn.report.interval, verifying client AM launch is detected before that interval elapses. Author: Marcelo Vanzin <vanzin@cloudera.com> Closes #18380 from vanzin/SPARK-16019.
-
- Jul 05, 2017
-
-
Dongjoon Hyun authored
## What changes were proposed in this pull request? This PR aims to bump Py4J in order to fix the following float/double bug. Py4J 0.10.5 fixes this (https://github.com/bartdag/py4j/issues/272) and the latest Py4J is 0.10.6. **BEFORE** ``` >>> df = spark.range(1) >>> df.select(df['id'] + 17.133574204226083).show() +--------------------+ |(id + 17.1335742042)| +--------------------+ | 17.1335742042| +--------------------+ ``` **AFTER** ``` >>> df = spark.range(1) >>> df.select(df['id'] + 17.133574204226083).show() +-------------------------+ |(id + 17.133574204226083)| +-------------------------+ | 17.133574204226083| +-------------------------+ ``` ## How was this patch tested? Manual. Author: Dongjoon Hyun <dongjoon@apache.org> Closes #18546 from dongjoon-hyun/SPARK-21278.
-
- Jun 21, 2017
-
-
Li Yichao authored
## What changes were proposed in this pull request? Currently the shuffle service registration timeout and retry has been hardcoded. This works well for small workloads but under heavy workload when the shuffle service is busy transferring large amount of data we see significant delay in responding to the registration request, as a result we often see the executors fail to register with the shuffle service, eventually failing the job. We need to make these two parameters configurable. ## How was this patch tested? * Updated `BlockManagerSuite` to test registration timeout and max attempts configuration actually works. cc sitalkedia Author: Li Yichao <lyc@zhihu.com> Closes #18092 from liyichao/SPARK-20640.
-
- Jun 19, 2017
-
-
sharkdtu authored
[SPARK-21138][YARN] Cannot delete staging dir when the clusters of "spark.yarn.stagingDir" and "spark.hadoop.fs.defaultFS" are different ## What changes were proposed in this pull request? When I set different clusters for "spark.hadoop.fs.defaultFS" and "spark.yarn.stagingDir" as follows: ``` spark.hadoop.fs.defaultFS hdfs://tl-nn-tdw.tencent-distribute.com:54310 spark.yarn.stagingDir hdfs://ss-teg-2-v2/tmp/spark ``` The staging dir can not be deleted, it will prompt following message: ``` java.lang.IllegalArgumentException: Wrong FS: hdfs://ss-teg-2-v2/tmp/spark/.sparkStaging/application_1496819138021_77618, expected: hdfs://tl-nn-tdw.tencent-distribute.com:54310 ``` ## How was this patch tested? Existing tests Author: sharkdtu <sharkdtu@tencent.com> Closes #18352 from sharkdtu/master.
-
- Jun 15, 2017
-
-
Michael Gummelt authored
## What changes were proposed in this pull request? Move Hadoop delegation token code from `spark-yarn` to `spark-core`, so that other schedulers (such as Mesos), may use it. In order to avoid exposing Hadoop interfaces in spark-core, the new Hadoop delegation token classes are kept private. In order to provider backward compatiblity, and to allow YARN users to continue to load their own delegation token providers via Java service loading, the old YARN interfaces, as well as the client code that uses them, have been retained. Summary: - Move registered `yarn.security.ServiceCredentialProvider` classes from `spark-yarn` to `spark-core`. Moved them into a new, private hierarchy under `HadoopDelegationTokenProvider`. Client code in `HadoopDelegationTokenManager` now loads credentials from a whitelist of three providers (`HadoopFSDelegationTokenProvider`, `HiveDelegationTokenProvider`, `HBaseDelegationTokenProvider`), instead of service loading, which means that users are not able to implement their own delegation token providers, as they are in the `spark-yarn` module. - The `yarn.security.ServiceCredentialProvider` interface has been kept for backwards compatibility, and to continue to allow YARN users to implement their own delegation token provider implementations. Client code in YARN now fetches tokens via the new `YARNHadoopDelegationTokenManager` class, which fetches tokens from the core providers through `HadoopDelegationTokenManager`, as well as service loads them from `yarn.security.ServiceCredentialProvider`. Old Hierarchy: ``` yarn.security.ServiceCredentialProvider (service loaded) HadoopFSCredentialProvider HiveCredentialProvider HBaseCredentialProvider yarn.security.ConfigurableCredentialManager ``` New Hierarchy: ``` HadoopDelegationTokenManager HadoopDelegationTokenProvider (not service loaded) HadoopFSDelegationTokenProvider HiveDelegationTokenProvider HBaseDelegationTokenProvider yarn.security.ServiceCredentialProvider (service loaded) yarn.security.YARNHadoopDelegationTokenManager ``` ## How was this patch tested? unit tests Author: Michael Gummelt <mgummelt@mesosphere.io> Author: Dr. Stefan Schimanski <sttts@mesosphere.io> Closes #17723 from mgummelt/SPARK-20434-refactor-kerberos.
-
- Jun 11, 2017
-
-
Michael Gummelt authored
## What changes were proposed in this pull request? Add Mesos labels support to the Spark Dispatcher ## How was this patch tested? unit tests Author: Michael Gummelt <mgummelt@mesosphere.io> Closes #18220 from mgummelt/SPARK-21000-dispatcher-labels.
-
- Jun 01, 2017
-
-
Li Yichao authored
In Spark on YARN, when configuring "spark.yarn.jars" with local jars (jars started with "local" scheme), we will get inaccurate classpath for AM and containers. This is because we don't remove "local" scheme when concatenating classpath. It is OK to run because classpath is separated with ":" and java treat "local" as a separate jar. But we could improve it to remove the scheme. Updated `ClientSuite` to check "local" is not in the classpath. cc jerryshao Author: Li Yichao <lyc@zhihu.com> Author: Li Yichao <liyichao.good@gmail.com> Closes #18129 from liyichao/SPARK-20365.
-
- May 25, 2017
-
-
Lior Regev authored
## What changes were proposed in this pull request? Deleted generated JARs archive after distribution to HDFS ## How was this patch tested? Please review http://spark.apache.org/contributing.html before opening a pull request. Author: Lior Regev <lioregev@gmail.com> Closes #17986 from liorregev/master.
-
- May 22, 2017
-
-
Marcelo Vanzin authored
Restore code that was removed as part of SPARK-17979, but instead of using the deprecated env variable name to propagate the class path, use a new one. Verified by running "./bin/spark-class o.a.s.executor.CoarseGrainedExecutorBackend" manually. Author: Marcelo Vanzin <vanzin@cloudera.com> Closes #18037 from vanzin/SPARK-20814.
-
- May 10, 2017
-
-
NICHOLAS T. MARION authored
## What changes were proposed in this pull request? Add stripXSS and stripXSSMap to Spark Core's UIUtils. Calling these functions at any point that getParameter is called against a HttpServletRequest. ## How was this patch tested? Unit tests, IBM Security AppScan Standard no longer showing vulnerabilities, manual verification of WebUI pages. Author: NICHOLAS T. MARION <nmarion@us.ibm.com> Closes #17686 from n-marion/xss-fix.
-
- May 08, 2017
-
-
jerryshao authored
## What changes were proposed in this pull request? After SPARK-10997, client mode Netty RpcEnv doesn't require to start server, so port configurations are not used any more, here propose to remove these two configurations: "spark.executor.port" and "spark.am.port". ## How was this patch tested? Existing UTs. Author: jerryshao <sshao@hortonworks.com> Closes #17866 from jerryshao/SPARK-20605.
-
Xianyang Liu authored
## What changes were proposed in this pull request? Currently, `spark.executor.instances` is deprecated in `spark-env.sh`, because we suggest config it in `spark-defaults.conf` or other config file. And also this parameter is useless even if you set it in `spark-env.sh`, so remove it in this patch. ## How was this patch tested? Existing tests. Please review http://spark.apache.org/contributing.html before opening a pull request. Author: Xianyang Liu <xianyang.liu@intel.com> Closes #17881 from ConeyLiu/deprecatedParam.
-
liuxian authored
Signed-off-by: liuxian <liu.xian3zte.com.cn> ## What changes were proposed in this pull request? When the input parameter is null, may be a runtime exception occurs ## How was this patch tested? Existing unit tests Author: liuxian <liu.xian3@zte.com.cn> Closes #17796 from 10110346/wip_lx_0428.
-
- May 03, 2017
-
-
Sean Owen authored
## What changes were proposed in this pull request? Fix build warnings primarily related to Breeze 0.13 operator changes, Java style problems ## How was this patch tested? Existing tests Author: Sean Owen <sowen@cloudera.com> Closes #17803 from srowen/SPARK-20523.
-
- Apr 27, 2017
-
-
Davis Shepherd authored
## What changes were proposed in this pull request? Add test case for scenarios where executor.cores is set as a (non)divisor of spark.cores.max This tests the change in #17786 ## How was this patch tested? Ran the existing test suite with the new tests dbtsai Author: Davis Shepherd <dshepherd@netflix.com> Closes #17788 from dgshep/add_mesos_test.
-
Davis Shepherd authored
## What changes were proposed in this pull request? Set maxCores to be a multiple of the smallest executor that can be launched. This ensures that we correctly detect the condition where no more executors will be launched when spark.cores.max is not a multiple of spark.executor.cores ## How was this patch tested? This was manually tested with other sample frameworks measuring their incoming offers to determine if starvation would occur. dbtsai mgummelt Author: Davis Shepherd <dshepherd@netflix.com> Closes #17786 from dgshep/fix_mesos_max_cores.
-
- Apr 26, 2017
-
-
Mark Grover authored
This change does a more thorough redaction of sensitive information from logs and UI Add unit tests that ensure that no regressions happen that leak sensitive information to the logs. The motivation for this change was appearance of password like so in `SparkListenerEnvironmentUpdate` in event logs under some JVM configurations: `"sun.java.command":"org.apache.spark.deploy.SparkSubmit ... --conf spark.executorEnv.HADOOP_CREDSTORE_PASSWORD=secret_password ..." ` Previously redaction logic was only checking if the key matched the secret regex pattern, it'd redact it's value. That worked for most cases. However, in the above case, the key (sun.java.command) doesn't tell much, so the value needs to be searched. This PR expands the check to check for values as well. ## How was this patch tested? New unit tests added that ensure that no sensitive information is present in the event logs or the yarn logs. Old unit test in UtilsSuite was modified because the test was asserting that a non-sensitive property's value won't be redacted. However, the non-sensitive value had the literal "secret" in it which was causing it to redact. Simply updating the non-sensitive property's value to another arbitrary value (that didn't have "secret" in it) fixed it. Author: Mark Grover <mark@apache.org> Closes #17725 from markgrover/spark-20435.
-
- Apr 24, 2017
-
-
Josh Rosen authored
This patch bumps the master branch version to `2.3.0-SNAPSHOT`. Author: Josh Rosen <joshrosen@databricks.com> Closes #17753 from JoshRosen/SPARK-20453.
-
- Apr 23, 2017
-
-
郭小龙 10207633 authored
[SPARK-20385][WEB-UI] Submitted Time' field, the date format needs to be formatted, in running Drivers table or Completed Drivers table in master web ui. ## What changes were proposed in this pull request? Submitted Time' field, the date format **needs to be formatted**, in running Drivers table or Completed Drivers table in master web ui. Before fix this problem e.g. Completed Drivers Submission ID **Submitted Time** Worker State Cores Memory Main Class driver-20170419145755-0005 **Wed Apr 19 14:57:55 CST 2017** worker-20170419145250-zdh120-40412 FAILED 1 1024.0 MB cn.zte.HdfsTest please see the attachment:https://issues.apache.org/jira/secure/attachment/12863977/before_fix.png After fix this problem e.g. Completed Drivers Submission ID **Submitted Time** Worker State Cores Memory Main Class driver-20170419145755-0006 **2017/04/19 16:01:25** worker-20170419145250-zdh120-40412 FAILED 1 1024.0 MB cn.zte.HdfsTest please see the attachment:https://issues.apache.org/jira/secure/attachment/12863976/after_fix.png 'Submitted Time' field, the date format **has been formatted**, in running Applications table or Completed Applicationstable in master web ui, **it is correct.** e.g. Running Applications Application ID Name Cores Memory per Executor **Submitted Time** User State Duration app-20170419160910-0000 (kill) SparkSQL::10.43.183.120 1 5.0 GB **2017/04/19 16:09:10** root RUNNING 53 s **Format after the time easier to observe, and consistent with the applications table,so I think it's worth fixing.** ## How was this patch tested? (Please explain how this patch was tested. E.g. unit tests, integration tests, manual tests) (If this patch involves UI changes, please attach a screenshot; otherwise, remove this) Please review http://spark.apache.org/contributing.html before opening a pull request. Author: 郭小龙 10207633 <guo.xiaolong1@zte.com.cn> Author: guoxiaolong <guo.xiaolong1@zte.com.cn> Author: guoxiaolongzte <guo.xiaolong1@zte.com.cn> Closes #17682 from guoxiaolongzte/SPARK-20385.
-
- Apr 17, 2017
-
-
Andrew Ash authored
## What changes were proposed in this pull request? Typo fix: distitrbuted -> distributed ## How was this patch tested? Existing tests Author: Andrew Ash <andrew@andrewash.com> Closes #17664 from ash211/patch-1.
-
- Apr 16, 2017
-
-
Ji Yan authored
[SPARK-19740][MESOS] Add support in Spark to pass arbitrary parameters into docker when running on mesos with docker containerizer ## What changes were proposed in this pull request? Allow passing in arbitrary parameters into docker when launching spark executors on mesos with docker containerizer tnachen ## How was this patch tested? Manually built and tested with passed in parameter Author: Ji Yan <jiyan@Jis-MacBook-Air.local> Closes #17109 from yanji84/ji/allow_set_docker_user.
-
- Apr 12, 2017
-
-
hyukjinkwon authored
## What changes were proposed in this pull request? This PR proposes to run Spark unidoc to test Javadoc 8 build as Javadoc 8 is easily re-breakable. There are several problems with it: - It introduces little extra bit of time to run the tests. In my case, it took 1.5 mins more (`Elapsed :[94.8746569157]`). How it was tested is described in "How was this patch tested?". - > One problem that I noticed was that Unidoc appeared to be processing test sources: if we can find a way to exclude those from being processed in the first place then that might significantly speed things up. (see joshrosen's [comment](https://issues.apache.org/jira/browse/SPARK-18692?focusedCommentId=15947627&page=com.atlassian.jira.plugin.system.issuetabpanels:comment-tabpanel#comment-15947627)) To complete this automated build, It also suggests to fix existing Javadoc breaks / ones introduced by test codes as described above. There fixes are similar instances that previously fixed. Please refer https://github.com/apache/spark/pull/15999 and https://github.com/apache/spark/pull/16013 Note that this only fixes **errors** not **warnings**. Please see my observation https://github.com/apache/spark/pull/17389#issuecomment-288438704 for spurious errors by warnings. ## How was this patch tested? Manually via `jekyll build` for building tests. Also, tested via running `./dev/run-tests`. This was tested via manually adding `time.time()` as below: ```diff profiles_and_goals = build_profiles + sbt_goals print("[info] Building Spark unidoc (w/Hive 1.2.1) using SBT with these arguments: ", " ".join(profiles_and_goals)) + import time + st = time.time() exec_sbt(profiles_and_goals) + print("Elapsed :[%s]" % str(time.time() - st)) ``` produces ``` ... ======================================================================== Building Unidoc API Documentation ======================================================================== ... [info] Main Java API documentation successful. ... Elapsed :[94.8746569157] ... Author: hyukjinkwon <gurwls223@gmail.com> Closes #17477 from HyukjinKwon/SPARK-18692.
-
- Apr 10, 2017
-
-
Sean Owen authored
[SPARK-20156][CORE][SQL][STREAMING][MLLIB] Java String toLowerCase "Turkish locale bug" causes Spark problems ## What changes were proposed in this pull request? Add Locale.ROOT to internal calls to String `toLowerCase`, `toUpperCase`, to avoid inadvertent locale-sensitive variation in behavior (aka the "Turkish locale problem"). The change looks large but it is just adding `Locale.ROOT` (the locale with no country or language specified) to every call to these methods. ## How was this patch tested? Existing tests. Author: Sean Owen <sowen@cloudera.com> Closes #17527 from srowen/SPARK-20156.
-
- Apr 06, 2017
-
-
Kalvin Chau authored
## What changes were proposed in this pull request? Add spark.mesos.task.labels configuration option to add mesos key:value labels to the executor. "k1:v1,k2:v2" as the format, colons separating key-value and commas to list out more than one. Discussion of labels with mgummelt at #17404 ## How was this patch tested? Added unit tests to verify labels were added correctly, with incorrect labels being ignored and added a test to test the name of the executor. Tested with: `./build/sbt -Pmesos mesos/test` Please review http://spark.apache.org/contributing.html before opening a pull request. Author: Kalvin Chau <kalvin.chau@viasat.com> Closes #17413 from kalvinnchau/mesos-labels.
-
- Apr 04, 2017
-
-
Marcelo Vanzin authored
Current test code tries to override the RackResolver used by setting configuration params, but because YARN libs statically initialize the resolver the first time it's used, that means that those configs don't really take effect during Spark tests. This change adds a wrapper class that easily allows tests to override the behavior of the resolver for the Spark code that uses it. Author: Marcelo Vanzin <vanzin@cloudera.com> Closes #17508 from vanzin/SPARK-20191.
-
- Mar 29, 2017
-
-
jerryshao authored
## What changes were proposed in this pull request? Currently we use system classloader to find HBase jars, if it is specified by `--jars`, then it will be failed with ClassNotFound issue. So here changing to use child classloader. Also putting added jars and main jar into classpath of submitted application in yarn cluster mode, otherwise HBase jars specified with `--jars` will never be honored in cluster mode, and fetching tokens in client side will always be failed. ## How was this patch tested? Unit test and local verification. Author: jerryshao <sshao@hortonworks.com> Closes #17388 from jerryshao/SPARK-20059.
-
- Mar 28, 2017
-
-
jerryshao authored
[SPARK-19995][YARN] Register tokens to current UGI to avoid re-issuing of tokens in yarn client mode ## What changes were proposed in this pull request? In the current Spark on YARN code, we will obtain tokens from provided services, but we're not going to add these tokens to the current user's credentials. This will make all the following operations to these services still require TGT rather than delegation tokens. This is unnecessary since we already got the tokens, also this will lead to failure in user impersonation scenario, because the TGT is granted by real user, not proxy user. So here changing to put all the tokens to the current UGI, so that following operations to these services will honor tokens rather than TGT, and this will further handle the proxy user issue mentioned above. ## How was this patch tested? Local verified in secure cluster. vanzin tgravescs mridulm dongjoon-hyun please help to review, thanks a lot. Author: jerryshao <sshao@hortonworks.com> Closes #17335 from jerryshao/SPARK-19995.
-
























